
September 14, 2007
Google Hot Trends
Поток с 100 Google Hot Trends за последний час. Обновляется, соответственно, тоже ежечасно. Просто чтобы адресок не потерять! :)
Написано Cherny в 2:04 PM | Комментариев (3) | TrackBack
July 31, 2007
Как посмотреть supplemental results
Старый трюк для выдачи списка страниц, попавших в supplemental results уже не работает.
Сегодня встречаем новый спецзапрос сезона Лето-2007 по выдаче страниц supplemental results (via):
Написано Cherny в 12:20 AM | Комментариев (0) | TrackBack
July 27, 2007
Подчеркивание в адресе будет разделителем
На сегодняшний день или в ближайшем будущем подчеркивание в адресе будет интерпретироваться Гуглем как разделитель слов (отсюда и отсюда). Об этом заявил Мэтт Каттс на конференции Word Camp. Казалось бы оптимзаторы могут расслабиться, а разработчики могут использовать столь любимые ими подчеркивания в адресе? Я так не думаю. Требование использовать дефисы в адресе я всегда аргументировал двумя пунктами: во-первых, разделитель слов в адресе для Гугля, во-вторых, подчеркивание в адресе как символ будет сливаться с подчеркиванием ссылки. Второе следует учитывать даже если при помощи стилей ссылки на сайте визуально выполнены без подчеркивания, никому не известно кто и где может поставить ссылку на вашу страницу. Есть еще в-третьих: подчеркивание в имени домена недопустимо, поэтому доменные имена так и продолжат резать на слова дефисами. Дефисы в имени домена, кстати, тоже не очень хорошо с точки зрения юзабилити, особенно для американских пользователей, но это уже совсем другая история.
Написано Cherny в 9:18 AM | Комментариев (4) | TrackBack
July 17, 2007
Google не будет нас помнить до 2038 года
Google в официальном блоге заявляет о планах сократить время хранения cookies, указывающих на настройки пользователя, до 2 лет. Большинство в курсе, что некоторые cookie с сайтов Гугля устанавливаются со сроком действия до 2038 года. Вот как раз этот срок и планируется существенно уменьшить. Это будет следующий шаг после анонимизации логов (удаления из логов ID кук и IP адресов) по улучшению privacy. Пишут, что в результате изучения пользовательских отзывов и консультаций с адвокатами.
Я попробовал удалить куки Гугля и получил их снова со сроком действия до того же 2038 года, будем дальше посмотреть.
Написано Cherny в 9:40 AM | Комментариев (1) | TrackBack
May 14, 2007
Нелинейность видимого PageRank
Очень яркая и доступная иллюстрация нелинейности видимых в тулбаре значений PageRank (via):
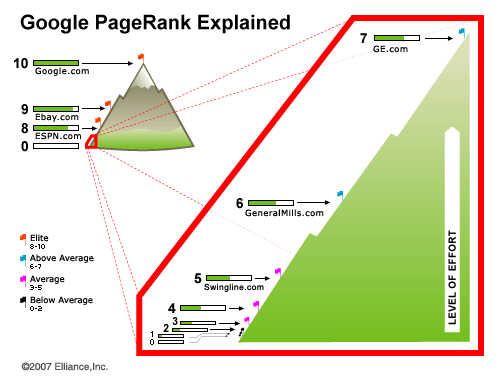
Хорошо видно, что от 6-ки до 7-ки может быть столько же, как до 6-ки от нуля! А все, что выше 7-ки — удел профессионалов с кислородными масками и спецснаряжением. Радует, что не одним PageRank'ом делается ранжирование, хотя от веса страницы зависят как позиции самой страницы, так и эффект ссылок на ней.
Написано Cherny в 10:30 AM | Комментариев (6) | TrackBack
March 20, 2007
Индексация результатов поиска
Пару недель назад Мэтт Каттс четко ответил на вопрос «Следует ли вебмастерам запрещать индексацию результатов поиска?», в результате изменили и руководство для вебмастеров:
Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don’t add much value for users coming from search engines.
Из фразы ясно, что вебмастер должен использовать правила в robots.txt, с помощью которых запрещать страницы с результатами поиска. В примерах Яндекса явно не указаны результаты поиска, как нежелательный контент, но такие приемы не понравятся модератору, особенно если результаты поиска формируются при помощи Яндекс.XML и на них ставятся статические ссылки. А такими методами в последнее время балуется один из украинских порталов, получающий значительный поисковый трафик именно на результаты поиска.
Еще ссылки по теме:
http://www.seroundtable.com/archives/012671.html
http://searchengineland.com/070312-104201.php
Написано Cherny в 11:10 AM | Комментариев (5)
March 3, 2007
Китайский Zeitgeist
Интрига продержалась недолго, скорее всего это будет китайская версия Google Zeitgeist, а Rebang можно перевести с китайского как Hot Ranking.
Написано Cherny в 10:35 AM | Комментариев (1)
February 28, 2007
Актеры для фильма о Google
Филипп Ленссен подбирает актеров на роли руководящего состава Google, если фильм о Google в ближайшее время будет сниматься. Сергея Брина, например, может сыграть Адам Сендлер. По ссылке есть таблица с фотографиями, наибольшее сходство у президента Китая, которого будет играть сам президент Китая :)
Написано Cherny в 10:38 AM | Комментариев (1) | TrackBack
February 27, 2007
Новые сервисы Google и robots.txt
Многие заинтересованные лица узнавали о новых сервисах Google из его robots.txt, где заранее запрещалась индексация страниц нового сервиса.
Сегодня Филипп Ленссен спрашивает, что такое «rebang», поскольку в файле исключений появилась новая запись: Disallow: /rebang
Написано Cherny в 10:13 AM | Комментариев (0) | TrackBack
February 22, 2007
За сколько произойдет склейка зеркал в Google
Barry Schwartz указывает на обсуждение в Google Groups, Где Адам Ласник называет время «суммирования» PageRank при склейке зеркал сайта 301-м редиректом. Адам говорит о нескольких неделях, Barry удивлен такому заявлению и выдвигает свой вариант в несколько месяцев:
I was a bit shocked by the statement of just "a couple of weeks" for 301s to "pass PR and related signals appropriately." I always thought it was a couple months or more.
В комментариях кто-то отметил год, в течение которого наблюдается разный PageRank на склеенных зеркалах. Меня лично удивляет сама возможность узнать достоверный PageRank для страницы, которая отдает серверный редирект. Узнать-то можно, но вот насколько это будет достоверно? Кроме этого не стоит забывать о частоте выкладывания значений «видимого» PageRank — один раз в несколько месяцев. Так что не стоит ждать быстрой склейки зеркал при помощи 301-го редиректа.
Написано Cherny в 3:17 PM | Комментариев (5) | TrackBack
February 12, 2007
Ловим рекламные переходы
Пару недель назад Мэтт Каттс рассказывал об отслеживании переходов с рекламных объявлений да и не только с них. Его повествование свелось к тому, что следует использовать auto-tagging в AdWords. Однако не все так просто, да и не везде такие механизмы можно найти. В чем же заключается проблема «меток» и как отследить переходы с рекламных объявлений, ссылок и баннеров?
Воспользуемся рисунком Мэтта. Чтобы отследить переход, к адресу страницы как правило добавляют специальную метку, по запросам такого URL с меткой и определяют количество нужных переходов. Если на рисунке присмотреться к пути пользователя по сайту, то переходы B и D сгенерируют дополнительные запросы к странице, которые можно ошибочно посчитать за клики по рекламным объявлениям. Однако это не все, есть еще некоторые моменты, например индексация и попадание страницы с параметром в индекс поисковых систем, а там, бывает, эта страница выбирается основной, а без параметра — дублем. Особенно обидно, когда это главная страница сайта. Что можно и нужно делать в этих случаях:
{kind=link}
- Следует запретить индексирование ссылки на странице с рекламой с помощью тегов noindex и параметра ссылки nofollow, хотя это больше для страховки;
- Запретить индексацию входных страниц с параметром, при этом разрешить индексировать страницы с параметром;
- Поставить серверный редирект со страницы с параметром основную страницу. Таким простым способом мы избежим повторных запросов при релоаде страниц и повторных заходах, даже кнопка back браузера отработает сразу на исходный адрес.
А что же это за auto-tagging?
Да ничего особенного — механизм добавляет к адресу целевой страницы динамическую часть с уникальным идентификатором, а количество переходов отслеживается по количеству уникальных меток. Однако это не избавляет схему от таких случаев, когда пользователь просто кинет ссылку с меткой в какой-нибудь форум и разбирайся потом, кто все эти люди, заходящие на страницу с одной и той же меткой, редирект при этом тоже не помешает, так что «На Google надейся, а сам не плошай!»
Написано Cherny в 12:45 AM | Комментариев (1) | TrackBack
February 6, 2007
Как в Гугле посмотреть ссылающиеся страницы
Всем известно (я так думаю), что ссылающиеся страницы в Гугле можно посмотреть с помощью оператора link:. Не все знают, что данный оператор показывает далеко не все ссылающиеся страницы, а только некоторые из них, так сказать для ознакомления. Поэтому пользоваться оператором link не очень удобно, а скорее очень неудобно!
Со вчерашнего дня в Google Webmaster Tools воспользовавшись вкладкой «Ссылки» можно смотреть более полный список ссылающихся страниц. Не все, но много больше, чем по стандартному оператору. Причем весь список разделяется на внешние ссылки и ссылки с того же домена (внутренние), список сгруппирован по страницам сайта, на которые стоят ссылки. Список также можно загрузить в Excel в формате CSV.

Все, что нужно для просмотра списка ссылающихся страниц — верификация сайта в системе.
Написано Cherny в 10:43 AM | Комментариев (1)
January 31, 2007
Google словарь
Филипп Ленссен публикует неофициальный Google-словарь. Объяснения терминов, начиная от beta и заканчивая Google Sucks - домен GoogleSucks.com принадлежит Google и пока непонятно, какой же сервис будет запущен на этом домене. :)
Написано Cherny в 10:41 PM | Комментариев (1)
January 27, 2007
Google говорит нет Googlebombing
В блоге для веб мастеров представители Google заявляют об изменениях в алгоритме поиска, благодаря которым должно исчезнуть такое явление, как Googlebombing. Денни Салливан, в свою очередь, дает ретроспективу этого явления и разбирает вопрос корректности решения этой проблемы, если Googlebombing можно назвать проблемой.
Технология Googlebombing сама по себе довольно проста и основывается на особенностях поисковых алгоритмов некоторых поисковых систем, а именно — учете текста ссылок при определении рейтинга страниц, на которые эти ссылки ведут, или ссылочном ранжировании. То есть слова из ссылки как бы добавляются к текст страницы, причем с учетом веса ссылающейся страницы. Ссылочное ранжирования хорошо работает в Гугл и даже слишком хорошо — в Яндексе. А вот Рамблер как ни бомби — толку будет мало. Если же к этому рецепту присовокупить социальную составляющую (выражаясь модными словами), а проще говоря — если поставить значительное количество ссылок с одинаковым текстом с разных сайтов на одну и ту же страницу, то эта страница займет хорошие позиции по запросу, даже если слова из запроса совсем не встречаются в тексте страницы.
Наиболее известным примером Googlebombing считается первое место страницы с биографией Джорджа Буша по запросу miserable failure (жалкий неудачник), причем первое место страница удерживала более двух лет. Аналогичные фокусы проделывались и в рунете с сайтами президента России Путина в 2006 году и кандидата в президенты Украины Януковича в 2004. Правда американской стабильности в нашем случае замечено не было — сайты в топах по бомбовым запросам долго не висели.
В Гугле не корректировали результаты поиска «вручную», а предпочли изменить алгоритм. Об изменениях алгоритма рассуждает Филипп Ленссен, кроме этого дает сравнительную таблицу наиболее известных случаев бомбинга, включая и российский случай. Филипп пишет, что следует анализировать структуру ссылочных графов для отсечения неестественных связей (ссылок) между узлами (страницами). Я же могу сказать, что для бомбинга характерно как отсутствие фразы в тексте самой страницы, так и одинаковый текст ссылок с большого количества страниц. А дальше уже анализ графов, конечно.
Написано Cherny в 12:40 AM | Комментариев (4)
January 26, 2007
А PageRank-то несвежий!
Алексей Тутубалин подсчитал, что значения тулбарного PageRank, обновление которого прошло в середине января, на самом деле относятся к середине ноября. То-то я смотрел, что у меня 0 там, где 4 как минимум. Полезность индикатора PageRank для вебмасетра и так низкая, разве только для продажи ссылок, а вот смотрят ли туда русскоязычные пользователи?
Написано Cherny в 11:08 AM
December 20, 2006
Контент и ссылки - два кита поискового продвижения
Контент и ссылки являются основными составляющими успешного поискового продвижения веб-сайтов. Ссылки входящие, конечно же! Там, где присутствует качественный контент, там с большой вероятностью появляются хорошие входящие ссылки, а сейчас, во время процветания различных веб-сервисов, можно утверждать и обратное: там где присутствуют ссылки, может появится и контент, но не факт, что качественный. И то, и другие, возможно только при наличии аудитории.
Но вернемся к ссылкам и контенту. Сотрудники Гугла после посещения профильных оптимизаторских и вебмастерских мероприятий и дискуссий, как у нас принято говорить, в кулуарах, решили ударить блогопробегом как по ссылкам, так и по контенту и вопросу его дублирования.
Ссылки
В первом посте рассматривается вопрос, как же лучше получать на свой сайт массив входящих ссылок — медленно наращивая его за счет качественного контента и грамотной стратегии продвижения или быстрыми темпами за счет применения не слишком чистых приемов и покупки ссылок. Примечательно, что покупка ссылок в данном посте явно приравнивается к спаму:
link spamming tactics such as buying links
Опуская обычные для таких случаев ссылки на руководство для вебмастеров, отметим следующие момент — Google существенно изменил алгоритм взвешивания ссылок, кроме этого несколько человек брошены на улучшение эффективности алгоритма. Я бы предположил добавление нескольких коэффициентов для довзвешивания ссылок, причем эти коэффициенты должны отличаться, например, для соседних ссылок на одной и той же страницы. Сообщается также о практической бесполезности взаимных ссылок, то есть прямого обмена, но это и так все знают.
В качестве рецепта рекомендуется использовать социальный веб для построения массива входящих ссылок. Хотя мне кажется, что социальный веб вполне себе освоил nofollow.
Кстати, алгоритм отлова нетематических невзаимных ссылок Игорь Ашманов нарисовал на листике бумаги во время фуршета на конференции, все довольно просто, надо отслеживать одинокие связи между "клубками" графа ссылок. Правда мне становится не очень хорошо, когда я пытаюсь представить ты часть ссылочного графа Яндекса, где сосредоточены коммерческие тематики.
Контент (дубликаты)
Во втором посте Адам Ласник дает определение дубликатам (duplicate content) и как обычный вебмастер может бороться с появлением таких дубликатов. Дубликаты - это блоки контента в пределах одного домена или ряда доменов, которые в точности соответствуют или сильно схожи на другие блоки контента, расположенные в других местах. Темы форумов в различных вариантах просмотра, сортировка списков, каталоги товаров, которые хранятся и, что намного хуже, линкуются по разным адресам (саттелиты не напоминает?)
Борется Гугл с дубликатами при помощи специальных фильтров при формировании результатов поиска, попытками отсеить версии для печати, корректировкой алгоритма индексации ресурсов, уличенных в дублировании и т.д.
Что же может сделать вебмастер? Некоторые методы я описывал в докладе о технических аспектах в поисковом продвижении, а вот что предлагают в Гугле:
- Изначально блокировать индексацию второстепенных страниц
- Использовать 301-й редирект при реструктуризации сайта для перенаправления на новые версии страниц
- Не генерить множество различных ссылок на одни и те же страницы
- Использовать домены второго уровня
- Понимать как работает CMS-сайта
И еще ряд рекомендаций...
Поскольку это все-таки запись в блоге, а не статья, то я здесь поставлю точку и пойду спать без ломания мозгов и формулирования выводов.
Написано Cherny в 1:03 AM
December 19, 2006
Полное запрещение индексации сайта
Сбылась мечта и... В общем, потребовалось на одном проекте полностью запретить индексацию поисковыми системами, от корня!
Нет ничего проще, две строчки в известном файле были прописаны 7-го декабря:User-agent: *
Disallow: /
Все поисковики ведут себя относительно прогнозируемо. Рамблер, например, проводит проверку запрещающих правил проиндексированным адресам раз в неделю, как правило на выходных, поэтому до выходных можно запрещать Рамблеру любые адреса из ранее проиндексированных и это ни на что не повлияет, они даже будут переиндексироваться, но на выходных карета превратится в тыкву, кони — в мышей, StackRambler сверится с актуальным robots.txt и выкинет все лишнее из базы.
Интересно ведет себя Google. После изменения robots.txt новые адреса, конечно, не индексируются, а уже известные — не переиндексируются заново, однако Гугл прикидывается шлангом и из индекса страницы не удаляет, там лежат сохраненные копии от 5-го декабря и ранее! Более 6 тысяч успешно сохраненных страниц! Хотя для Гугля это скорее правило, буквально на прошлой неделе я имел счастье лицезреть кеш страницы в дополнительном индексе (Supplemental Results) от середины апреля, причем всем роботам было запрещено индексировать страницу где-то в начале мая.
Таким образом Гугл интерпретирует запрещающее правило в robots.txt как запрет индексации и переиндексации, но не как требование удаления уже проиндексированной страницы из индекса.
Написано Cherny в 12:59 AM
December 14, 2006
Индексация и GoogleBar
Насколько я помню, пару лет назад существовало несколько базовых оптимизаторских заповедей, что-то вроде guideline. Среди прочего в этих ответах было утверждение, что Гугл не добавляет новые страницы в очередь на индексацию при помощи своего тулбара. На днях появились подробности о недавнем споре немецкого блоггера Филиппа Ленссена и сотрудника Google Мэтта Каттса о возможности индексации страниц при помощи тулбара.
Филипп предположил, что страницы могут индексироваться, поскольку для отображения в тулбаре значения PageRank в Гугл отправляется специальный запрос, в котором фигурирует адрес страницы. В случае отсутствия такого адреса в индексе, вполне возможно сразу же поставить его в очередь на индексацию:
it might be possible the Atom feed is now indexed via e.g. the Google Toolbar (which is known to get pages into the Google index even when those pages are unlinked)
...Google knows the URL of every page you visit if you enable the Google Toolbar advanced options, as it will send the URL to Google to check for the URL's PageRank. It was my understanding this also gets the page indexed
Мэтт там же ответил, что такое навряд ли возможно и попросил дать знать, если эта гипотеза подтвердится:
I don't believe that part in parentheses is true; let me know if you've got a source for that and I'll go and comment there..
В результате Филипп поставил несложный эксперимент: разместил у себя на сайте страницу с уникальным текстом, на которую не было внешних ссылок, после чего заходил на эту страницу браузером с установленным тулбаром просто набирая URL в адресной строке. Страница была создана в августе и до сего момента не находится по уникальному запросу.
В результате эксперимента было подтверждено, что страницы без каких-либо входящих ссылок не попадают в индекс Google только благодаря их открытию в браузере с гугл баром.
В обсуждении эксперимента всплыл еще один интересный вопрос: человек воспользовался стандартной формой добавления, но добавленная страница так и не появилась в индексе. Мэтт заметил, что они не гарантируют попадание в индекс страниц, адреса которых были получены с помощью формы добавления. Хотя сенсации из этого факта делать не стоит, я сталкивался с особенностями добавления страниц в индекс Google еще 6 лет назад, когда только начинал постигать азы, а тогда и деревья были выше, и трава зеленее, и роботы медленнее, и апдейты реже...
Я повторю эксперимент по включению в индекс страниц с помощью тулбаров, правда с некоторыми корректировками, тем более что есть еще один известный тулбар, с участием которого в индексации уже довелось сталкиваться! :)
Написано Cherny в 2:01 AM
December 13, 2006
Запустился Google News на русском
Я давно этого ждал — Google News уже на русском! Обрабатывается 400 новостных источников, что для старта вполне достаточно. Посещаемость новостного сервиса — 1% посетителей всех сервисов Google, а учитывая популярность сервисов Google по сравнению с другими российскими порталами, можно предположить не слишком большую аудиторию сервиса. Но это только начало.
Написано Cherny в 10:37 AM
December 6, 2006
Google переводит с английского на русский
В русскоязычной версии Google появились ссылки «Перевести эту страницу», если страница в результатах поиска на английском, по ссылке пользователь переходит на страницу, переведенную на русский «на лету».
Написано Cherny в 4:03 PM
December 1, 2006
SiteMaps для новостей Гугля
Ну вот и зима, пусть в прошлом остаются густые и мутные туманы, свинцовые тучи, осенняя депрессия и дорожная грязь. Где тот мороз и солнце, и день чудесный? А в это время где-то за границей…
Учимся говорить просто Sitemaps (пока) 0.9, а не Google Sitemaps, как раньше. Теперь можно при аудите простукивать еще файлик sitemaps.xml в корне сайта.
После подключения Sitemaps к Google.News стало совсем интересно! Хотя, конечно, отсутствие последних для России и Украины делает интерес скорее академическим, нежели практическим, тем более Sitemaps в новостях работает только в англоязычной части. Тем не менее: появилось описание работы сервиса с указанием ошибок обработки новостных сообщений для Google News.
При отсутсвующем русскоязычном сервисе хелп для него есть и из него можно узнать следующее:
Title not found (заголовок не найден) — из справки узнаем, что на странице отсутствует тег title с заголовком новости, кроме этого рекомендуется заголовок повторить на видном месте страницы, например в h1, сам заголовок должен быть не слишком коротким и не слишком длинным — от 2 до 22 слов. Так что заголовок новости "Поехали!" делать не стоит.
Article disproportionality short (статья непропорционально короткая) — из справки становится ясно, что текст самой новости составляет слишком маленькую часть всего контента страницы, так что нельзя делать короткие новостные сообщения.
Article fragmented (статья фрагментирована) — из справки: текст статьи не группируется в абзацы, а состоит из отдельных предложений.
No sentences found (не найдено ни одного предложения) — справка повторяет текст ошибки другими словами, а в источнике можно найти такую страницу.
Вот чем мне нравится Google News, что есть технические требования к разделу новостей, есть требования к контенту и верстке, а вот ссылки никакой роли не играют! :) Ну так это и не полностью машинный поиск - решение о включении ресурса в список новостных источников принимает модератор.
Когда Гугл будет заморачиваться с запуском новостного сервиса на русскоязычную аудиторию, когда будет у него достаточно этой аудитории или после решения более насущных вопросов?
Написано Cherny в 1:12 AM | Комментариев (1)
November 10, 2006
Яндекс о блогах, Google об индексации
Меня накрыл приступ сезонной депрессии — ничего не хочется делать, ничего не хочется писать, чтение логов не приносит радости… Но тем не менее:
- Сегодня в Киеве будет проходить Pub Conference, организованная Женей Шевченко, где я буду присутствовать.
- На следующей неделе конференция в Москве.
- В четверг, 16-го - оптимизаторская вечеринка в честь 6-летия форума.
- Хочу задержаться в Москве на выходные и погулять/посмотреть город.
Сегодня в своем блоге Яндекс рассказывает о принципах построения рейтинга блогов. Чтобы не развозить здесь все, что и так сказано там - используется комплексный подход в рейтинговании с использованием доступных данных о блоге, также присутствует и защита от накруток.
А Google продолжает просвещать вебмастеров о базовых принципах индексации сайтов. В посте дается один дельный совет, которым часто пренебрегают, выделение мое:
Of course, you (and we) only want one version of the URL to be returned in the search results. Not to worry -- this is exactly what happens. Our algorithms selects a version to include, and you can provide input on this selection process.
Мне часто приходится слышать вопрос: «Неужели робот Гугля/Яндекса/Рамблера не может правильно определить главную версию страницы/сайта/раздела? Там ведь все ясно!» Действительно, роботы поисковых систем работают по все более сложным алгоритмам и, в большинстве случаев, правильно определяют нужную страницу или зеркало. Однако бывает и наоборот, а исправить всегда сложнее, чем предотвратить. Если и не сложнее, то значительно дольше. Поэтому можно пользоваться следующим правилом:
Чтобы роботы поисковых систем сделали однозначно правильный на ваш взгляд выбор, надо просто не давать им делать этот выбор.
Другими словами надо заранее указывать главное зеркало, предотвращать индексацию страниц с другим порядком динамических параметров в адресе, ставить идентичные ссылки на главную страницу как с внутренних страниц, так и с других сайтов. И все будет тип-топ!
На сегодня все, до скорых встреч!
Написано Cherny в 2:42 PM
October 19, 2006
Нестандартные теги в RSS
Обнаружил ложку дегтя к некоторому количеству меда, связанному новыми инструментами Sitemaps - сервис сообщает об ошибках в нескольких моих потоках, причем раньше такого не было для тех же потоков. Ошибки появляются из-за употребления в RSS-потоках тегов, которых нет в стандарте: creator, subject. В ряде случаев (WordPress) я их повыкусываю, поскольку уже есть опыт рихтовки таких RSS, а кое-где такая рихтовка будет проблематичной, но там использование RSS не более чем приятное дополнение.
Написано Cherny в 3:21 PM
October 18, 2006
Скорость индексации в Гугле задается вручную!
В Google Webmaster Central добавлены очередные инструменты. Во-первых, это графики сканирования сайта: сколько страниц сайта индексируется в день, сколько килобайт в день загружено и сколько потрачено в среднем времения на загрузку одной страницы.
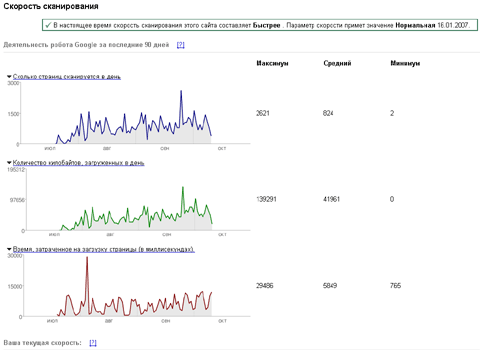
Данные представлены за последние 90 дней. Из графиков явно видна обратно пропорциональная зависимость между временем загрузки страницы и скоростью индексации, то есть как только сайт начинает притормаживать, GoogleBot снижает количество запросов для снижения нагрузки на сайт. А если сайт совсем не отвечает? Нет, не буду проводить эксперимент! :)
Во-вторых, на этой же странице добавлена форма регулирования скорости индексации.
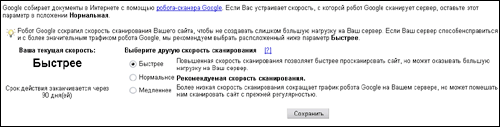
Над формой явно отмечено, что скорость индексации снижения для снижения нагрузки на сервер. Поставил быструю скорость, после чего получил сообщение о том, что данные настройки будут действительны до 16-го января, т.е. следующие три месяца.
Вот и ответ на вопросы о том, что GoogleBot грузит сервер, кроме того дополнительный аргумент для добавления сайта в Google SiteMaps.
Филипп Ленссен возмущается, что теперь придется каждую поисковую систему под свой сайт настраивать? Таки да, а расширение Crawl-delay разве не является той же самой настройкой, только для других систем?
Написано Cherny в 2:31 PM | Комментариев (3)
October 11, 2006
Google Docs
Google объединил текстовый редактор Writely и электронные таблицы Google SpreadSheet в единый интерфейс Google Docs (via).
Новый текстовый документ можно начать редактировать, просто отправив его на специальный e-mail адрес. А можно просто аплоадить документы. Среди поддерживаемых форматов фигурирует OpenOffice. Созданные и отредактированные документы затем можно сохранять локально, как файлы Word, PDF. Сохраняется история изменений документа, есть возможность откатить изменения.
Аналог Microsoft Office онлайн?
Написано Cherny в 2:53 PM
Осень пришла: апдейт Yahoo, PageRank не изменится до Нового Года
В официальном блоге Yahoo очередное сообщение об очередном апдейте, Мэтт Каттс пишет о прошедшем апдейте инфраструктуры Google в пятницу 6-го октября, недавнем экпорте видимых значений PageRank и говорит, что обновлений PageRank в тулбаре не планируется до Нового Года:
We just did a PageRank export, so I wouldn’t expect to see another export until the new year.
Написано Cherny в 10:56 AM
October 6, 2006
Pinging Service для Google BlogSearch
Google запустил Pinging Service для тех, кто не может найти свой сайт в поиске по блогам от Google. Кстати, последний, по сравнению с новой версией аналогичного сервиса от Яндекса, смотрится довольно убого.
Сервис предназначен для информирования Google об обновлениях в блоге. Сервис "одноразовый", то есть после следующего обновления надо снова отпинговаться. Ленивые могут воспользоваться соответствующим API.
Информация об активности сервиса за последние 5 минут экспортируется в XML, вот где надо смотреть последние обновления на блогах!
Написано Cherny в 12:24 AM | Комментариев (1)
October 3, 2006
Мэтт Каттс об апдейтах PageRank
Мэтт Каттс ответил на ряд вопросов о PageRank, его апдейтах и значениях. Ничего особо нового и секретного, все можно втиснуть в несколько строк:
- Видимый в баре PageRank обновляется один раз в несколько месяцев (апдейт начался в прошлую пятницу);
- Видимый в баре PageRank — представление реальных значений PageRank в шкале 0-10;
- Реальные значения PageRank вычисляются непрерывно для каждого URL в индексе поисковой машины, поэтому видимые в баре значения — лишь статичный снимок реальных значений в определенный момент времени (апдейт);
- Влияния на SERP оказывают именно текущие реальные значения PageRank.
Ну и все, собственно.
Написано Cherny в 11:15 AM
Механизм статистики поисковых запросов и кликов
На прошлой неделе Ванесса Фокс в блоге Google Webmaster Central расписала механизм отчетов по популярным поисковым запросам и по кликам в результатах поиска для сайтов в Google Sitemaps.
Если коротко, то схема работы следующая:
- Вычисляется поисковые запросы, по которым наибольшее количество пользователей видело сайт в результатах поиска
- Вычисляются средния значения по наилучшим позициям сайта в результатах поиска по выбранным поисковым запросам
- Для кликов вычисляются средние значения на основе позиций, с которых пользователи действительно кликали по ссылке на сайт
- Список поисковых запросов сортируется по количеству просмотров, при этом запрос с худшей позицией (но большим абсолютным количеством запросов) находится выше менее частотного запроса
- Просмотры вычисляются реальные, т.е. если позиция сайта по запросу «оптимизация сайта» 24, запрос задают 1000 раз в месяц, но до третьей страницы результатов добирается только 400 пользователей, то учитываться будет именно 400
Ну и обновляются результаты сейчас раз в неделю, а раньше обновлялись один раз в три недели. Все fresher и fresher.
Что же мы из этого всего можем поиметь. А можем мы грубо сравнить эффективность позиций по доступным запросам - если уж популярный запрос с худшей позицией в списке находится выше менее популярного, где сайт на первой позиции, то видит его больше людей. Хотя эффективность заголовка = текста ссылки и сниппета никто не отменял, а увидели — не значит перешли.
Как и ранее, можно посмотреть списки из различных поисковых сервисов: веб-поиск, мобильный поиск, поиск по изображениям, а также по регионам.
Написано Cherny в 12:20 AM
September 25, 2006
Роботы Гугл становятся российскими интернет-пользователями
Для сайтов, размещенных на мастерхосте, трафик, сгенерированный роботами Гугл, будет считаться российским, а не зарубежным.
Теперь можно не разбираться с ходом индексации сайтов со сложной структурой и не закрывать от индексации малоинформативные страницы, поменьше станет вопросов о том, что роботы слишком нагружают сайт. Хотя нет, нагружать будут так же, только уже почти свои, а со своими и разговор другой!
Написано Cherny в 10:04 PM
September 18, 2006
Имя домена в качестве поискового запроса
Мэтт Каттс рассказывает об изменении результатов поиска, когда запрос представляет собой имя домена. Раньше запрос имени домена был эквивалентен оператору info: для этого домена. Сейчас же не выполняется никаких подстановок и пользователь скорее всего получит ссылку на искомый сайт вместо непонятной информации: кешей, входящих ссылок и похожих страниц.
А вот зачем пользователи вгоняют в поисковую строку адрес сайта, если его можно просто набрать в адресной строке браузера? Пользователь может ничего и не знать об адресной строке — для него интернет начинается с поисковой строки любимого Яндекса/Google/Рамблера/MSN/Меты (нужное подчеркнуть). А подкованные интернет-деятели потом чешут затылки, почему это так много на Рамблере ищут www.yandex.ru, а на Яндексе — www.rambler.ru
Теперь можно ожидать некоторого увеличения трафика с Google по адресу сайта, если адрес сайта известен, конечно.
Написано Cherny в 10:44 PM | Комментариев (1)
September 15, 2006
Дополнительные результаты для сайта в Гугле
Появился новый хак для Гугля: узнать количество Дополнительных результатов (Supplemental Results) для сайта можно с помощью запроса: site:www.domain.tld ***
Для Амазона, например, это от 15 до 64 миллионов(!) страниц. Я вижу только 13 миллионов, но тоже немало.
Написано Cherny в 9:52 AM | Комментариев (1)
September 11, 2006
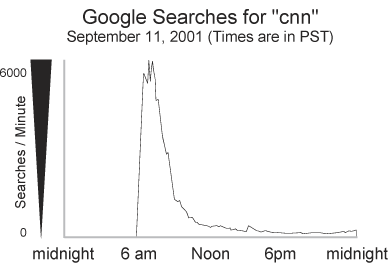
Статистика 5-летней давности
11 сентября 2001-го года WTC в Нью-Йорке и Пентагон в Вашингтоне по были атакованы террористами. В это время новостные сайты не справлялись с многократно возросшей нагрузкой, а на главной странице Google выложили ссылки на основные новостные сайты и закешированные копии их страниц. В районе 7-ми утра по калифорнийскому времени количество запросов "cnn" составляло 6000 в минуту или 100 запросов в секунду, "World Trade Center" — 2000 запросов в минуту.
Написано Cherny в 11:47 PM | Комментариев (3)
September 8, 2006
Google Sitelinks
Ну просто праздник какой-то!
После постов Дмитрия Честных и Артема Шкондина (и я отметился) Гугль решил все-таки сделать страницу с информацией о дополнительных ссылках в результатах поиска на другие страницы сайта.
Большим черпаком дегтя в этом горшочке меда от Гугл является полное отсутствие какой-либо конкретики, при каких условиях такие ссылки появляются:
We only show Sitelinks for results when we think they'll be useful to the user. If the structure of your site doesn't allow our algorithms to find good Sitelinks, or we don't think that the Sitelinks for your site are relevant for the user's query, we won't show them.
Зато есть термин — Sitelinks. Ну и на том спасибо.
Написано Cherny в 10:30 AM | Комментариев (3)
September 7, 2006
Дата в кеше Гугля
В Webmaster Central Blog появилось сообщение, где разъясняется изменение вывода даты над кешированной копией страницы. Ранее выводилась дата последнего успешного получения копии страницы Googlebot'ом. Если позже робот запрашивал страницу повторно и получал ответ сервера 304 Not Modified, дата не изменялась.
В настоящее время выводится дата последнего запроса страницы роботом, даже если сервер получил 304-й ответ. Таким образом, просмотрев кеш страницы, мы точно можем сказать, когда там последний раз был GoogleBot.
Написано Cherny в 11:41 PM
Ошибка в Google Help
Сегодня нарисовал такой robots.txt на одном сайте, что самому страшно стало. Зато проверим правильность работы основных роботов с документированными и не очень директивами.
Пока рисовал, натолкнулся в одном из разделов помощи Гугля на ошибку:
Для блокирования доступа ко всем URL, включающим вопросительный знак (?), можно использовать следующую запись:User-Agent: *
Allow: /*?*
Эта запись как раз позволит роботу Гугля индексировать все странице с вопросительными знаками в адресе, а не заблокирует. Ошибка повторяется в английском варианте тоже.
Если такую запись поместить в реальный robots.txt, то, по идее, на ней споткнутся все роботы, кроме Google: либо запись будет проигнорирована полностью, либо проигнорирована строка с Allow как не соответствующая стандарту. А поскольку ни одной строки с Disallow не наблюдается, то вся запись проигнорируется в любом случае. Я уже как-то писал, но повторюсь: нестандартные директивы следует применять только в собственной секции понимающего их робота.
Написано Cherny в 11:05 PM
September 6, 2006
AiK о дополнительных ссылка в Google SERP
Артем Шкондин подробно рассказывает о дополнительных ссылках в результатах поиска Google, когда они появляются и каким требованиям должны соответствовать ссылки на сайте, чтобы попасть в такие дополнительные секции.
Написано Cherny в 11:21 AM
August 29, 2006
Конструктор портала от Google
Гугл предлагает для установки на доменах пользователей четыре своих сервиса: почту на основе GMail, IM на основе Google Talk, календарь на основе Google Calendar и средство публикации страниц на основе Google Page Creator. Оформление, как то цветовые схемы, логотипы и прочее можно изменять, о хостинге и функциональности Гугл позаботится.
Как-то одному человеку понравилась моя фраза, что пользователи продолжают переносить свои данные на датацентры Гугля. Таки продолжают!
И еще рекомендую «Заметки разработчика поисковых сервисов», очень интересный журнал!
Написано Cherny в 8:57 AM | Комментариев (2)
Google Wireless Transcoder
Несмотря на большое количество различных лог-анализаторов и сервисов обсчета статистики, в том числе и заточенных под SEO, стоит иногда просто проглядывать логи.
Вот, например, выловился интересный зверь Google Wireless Transcoder. robots.txt он не запрашивает, никакого поясняющего URL в User-agent не указано.
Оказывается это специальный агент Google, подготавливающий контент для мобильников, причем не сканирующий, а именно преобразующий, не зря упоминается Transcoder.
Из особенностей поведения следует отметить несколько запросов графики с пустыми полями Referer и User-agent с того же IP. То есть забирается вся страница с графикой и преобразуется на лету, но при этом JavaScript не исполняется. CSS-ом тоже не интересуется.
Полный User-agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; Google Wireless Transcoder;)
Таким образом можно отловить читателей через мобильные устройства, нашедших контент в Гугле, только вот поискового запроса нет.
Написано Cherny в 12:47 AM
August 8, 2006
GWC - продолжение
Кроме самого сервиса, старый блог тоже переехал на новый адрес.
Остановлюсь подробнее на «фичах» Google Webmaster Central.
Изменения интерфейса
Сам интерфейс претерпел изменения. Более удобно стало просматривать информацию об индексировании, URL, запрещенные для индексации и т.д. На скриншоте я обвел ссылку на новый инструмент по указанию основного зеркала
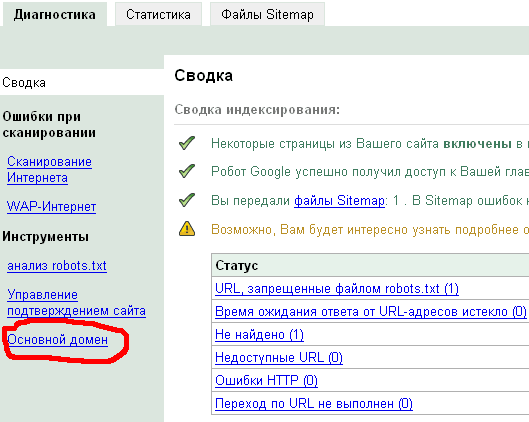
Выбор основного зеркала сайта
Вот как выглядит форма выбора основного адреса для домена — с www или без.

Выбор скорости индексации сайта
Форма выбора скорости индексации сайта в данный момент тестируется и показывается только малому количеству вебмастеров. У меня ссылки на нее нет, скриншот взял отсюда.
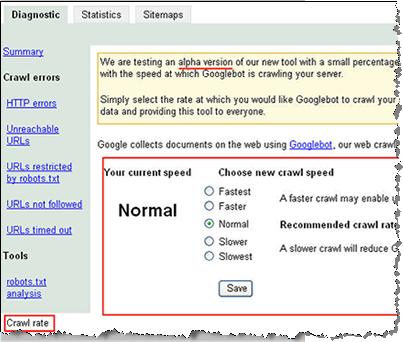
Статистика индексации самого Google
На следующем скриншоте из блога GWC можно рассмотреть статистику индексации Гуглом самого себя:
- HTTP-ошибок: 34
- Не найдено: 13617
- URL time out: 6
- Недоступных адресов: 1151
- Запрещено в robots.txt: 1493507

Написано Cherny в 9:20 AM | Комментариев (1)
August 7, 2006
Google Webmaster Central
В конце прошлой недели было объявлено о переименовании, или, как сейчас модно говорить, ребрендинге Google Sitemaps, на котором и был основан новый сервис, получивший название Google Webmaster Central.
Google продолжает поворачиваться к вебмастерам лицом! :)
Я отмечал полезность Google Sitemaps в своем докладе на майской конференции в Киеве, сервис продолжали развивать и усовершенствовать, сейчас интерфейс отслеживания ошибок на сайте стал более удобным и добавилось несколько новых инструментов. Наиболее интересный и важный — указание главного зеркала для домена, с www или без. Так что важность организации 301-го редиректа для Google несколько снизилась, хотя во многом он нам еще пригодится.
Несколько инструментов еще тестируются, например выбор скорости индексирования сайта.
Написано Cherny в 10:10 PM
August 4, 2006
Сериал о Google
Мэтт Каттс выложил целый сериал небольших видеообращений с ответами на ряд вопросов от вебмастеров. Довольно интересных вопросов, кстати.
Воспринимать на слух можно, хотя и не все сразу понятно. Добрые люди, однако, стенографировали и выкладывали в виде текстов (еще не все), так что нет необходимости вновь и вновь прокручивать видео.
Юмор в ответах обнаруживается, например часть ответа на вопрос о сравнении влияния тегов <b> и <strong> следует воспроизводить примерно так:
...потому что тег <b> использовали все с давних времен (когда динозавры бродили по Земле), а <strong> рекомендует использовать W3C. В настоящее время, прошлой ночью (30 июля 2006 года) я думал, что Google немножко, немножко, немно-о-ожко — как эпсилон — отдает больше приоритета тегу <b>, и я сказал, что по большей части не стоит об этом беспокоиться.
Однако хорошая новость заключается в том, что инженер показал мне часть кода, и я смог лично удостовериться, что Google учитывает теги <b> и <strong> с абсолютно одинаковым приоритетом...
В любом случае обязательно прослушать, прочитать, осознать, сделать выводы! Но это уже не сегодня, следите за анонсами.
Написано Cherny в 12:20 AM
August 1, 2006
Как работает Google News
Филипп Ленссен тезисно описывает принципы работы Google News. Переводить не буду, тем более никаких особых откровений там нет. Да и русскоязычной версии сервиса и источников пока нет, будем надеяться, что «пока»!
Следует отметить, что при всей схожести, Яндекс.Новости функционируют несколько по другому в области получения новостного контента.
Написано Cherny в 12:03 AM
July 25, 2006
Кто рисует праздничные логотипы Google
Вебмастер, рисующий праздничные логотипы Google вышел из подполья:
Деннис Хванг (Dennis Hwang), возможно, самый известный и, одновременно, неизвестный художник в мире: его работы не висят в галереях или музеях, но их видели сотни миллионов людей.
28-летний веб-мастер компании Google проектирует причудливые эмблемы, которые в специальных случаях украшают сайты компании, сообщает cnn.com
Написано Cherny в 10:14 AM
July 17, 2006
Описанию из ODP - нет!
В Google добавили обработку еще одного дополнительного метатега, чтобы в результатах поиска не использовалось описание сайта в ODP в качестве сниппета. Для на страницах сайта надо использовать один из вариантов:
<META NAME="ROBOTS" CONTENT="NOODP">
<META NAME="GOOGLEBOT" CONTENT="NOODP">
Некоторые шутят, что надо еще добавить обработку таких тегов, как:
<META NAME="GOOGLEBOT" CONTENT="NOBAN">
<META NAME="GOOGLEBOT" CONTENT="AlwaysFirstResult">
Написано Cherny в 10:35 AM | Комментариев (1)
July 14, 2006
Страшилка про редирект 301
Прочитал страшилку про 301-й редирект в Google:
Человек поставил 301-й редирект с сайта без www на сайт с www, после чего Google удалил все сраницы сайта из индекса. Человек прождал 10 месяцев (!), после чего удалил редирект и все страницы сайта с адресом без www вернулись в индекс чудесным образом.
Мистика какая-то...
Написано Cherny в 12:50 PM
July 4, 2006
Лафа для спамеров закончилась
Поскольку Мэтт Каттс возвращается из отпуска. Ждем сообщений об апдейтах, а также «закручивания гаек» спамерам и прочим нехорошим людям.
В особенности интересно, будет ли продолжение истории о клоакинге на сайте New York Times.
Написано Cherny в 9:25 AM | Комментариев (2)
June 22, 2006
Google добавляет в хелп секцию о robots.txt
Неделю назад в раздел Как Google сканирует мой сайт справки для вебмастеров добавлена секция Использование файла robots.txt, в частности такие вопросы как:
- Как создать файл robots.txt?
- Список различных агентов Google для строк User-agent, тут же описывается директива Allow, которая исключительно в Гугле и работает
- Использование шаблонов (символов подстановки), опять же, только в Гугл
- Как часто перезапрашивается robots.txt - раз в день
Хотя в некоторые статьи, так сказать, засрались очепятки. А именно в примерах следует отделять записи для разных роботов пустой строкой, как это записано в англоязычной версии этой же страницы. А вот в немецкой, испанской, русской и других версиях пустой строки не обнаруживается. Так что документацию следует читать на языке оригинала или периодически с оригиналом сверяться.
Неделю назад также появилось сообщение, что форма проверки robots.txt в Google Sitemaps выдает ошибку, если объем файла превышает 5000 символов. Это может быть как особенностью реализации формы проверки, так и оограничением робота при обработке файла исключений. Мне сложно представить даже довольно большой сайт, для которого надо писать почти 5-ти килобайтный robots.txt, это ж сколько всего запретного сгенерить надо! :)
Написано Cherny в 3:30 PM
June 21, 2006
Если бы веб-сайты были пультами ДУ
Если бы веб-сайты были пультами дистанционного управления. Google
Yahoo!

Больше здесь
Написано Cherny в 9:28 AM
June 15, 2006
ЧМ 2006 и поисковые системы
Поисковики по разному обыгрывают Чемпионат Мира по футболу в Германии.
Яндекс
На главной странице Яндекса опубликована ссылка на соответствующую ветку новостей, кроме этого в телепрограмме отдельным блоком трансляции матчей со временем и кратким анонсом.
Рамблер
Рамблер просто запустил отдельный проект FIFA-2006.
Если в Google ввести через пробел два названия стран, сборные которых играли в недавнем времени, то он просто выдаст счет матча, а также время следующего ближайшего матча одной из команд. По такому запросу, например, можно убедиться, что вчерашний матч нашей сборной не приснился мне в кошмарном сне! Хотя чуда ждать, конечно, не стоило...
Написано Cherny в 10:03 AM | Комментариев (2)
May 16, 2006
Google Notebook уже в эфире
Google NoteBook'ом уже можно пользоваться, для FireFox необходимо скачать расширение.
Дополнительно можно прочитать про возможности сервиса в блоге Филипа Ленссена.
Итак, пользователи продолжают миграцию своих данных в датацентры Гугля...
Написано Cherny в 1:48 PM | Комментариев (1)
May 15, 2006
GoogleBot воспользовался дырой в настройках веб-сервера
На прошлой неделе главный борец с веб-спамом в Google, еще до того, как представили Google Trends и Google Co-op описал довольно интересный случай из жизни GoogleBot и crawl/index team, проще говоря робототехников.
Суть вопроса заключалась в том, что Google показывал контент с одного сайта (А) под адресом другого (Б), причем и А, и Б висели на одном сервере (IP) как виртуальные хосты. Причем ни Yahoo, ни MSN таких вольностей себе не позволяли. Пришлось робототехникам разбираться, что же на самом деле творилось в процессе краулинга/индексации. Смоделировать ситуацию удалось с помощью telnet, оказалось, что проблема заключалась в неправильной настройке виртуальных хостов.
GoogleBot при индексации использует возможность протокола HTTP 1.1 не разрывать соединения после получения каждого документа, а получить несколько документов за один присест. Кто изучал серверные заголовки — копать в сторону Keep-Alive. Эту фичу внедрили как раз в версии 1.1 для того, чтобы можно было получить в пределах одного соединения не только саму веб-страницу, но и файл стилей и картинок как можно больше.
Вот и получилось, что сервер навыдавал роботу Гугля документов из разных виртуальных хостов в пределах одного соединения. Робот, конечно, very smart, в результате.
Кстати, о птичках! Для Supplemental Results (Дополнительных Результатов) не только база своя, но и робот отдельно-индексирующий?
Написано Cherny в 11:40 PM
April 25, 2006
Google: кеширование при индексировании
А в это время где-то за границей...
Владимир Путин: мы цены на газ для Украины не из носа выковыривали.
Украинская правда: В. Путин выковыривал цены на газ не из носа
Все наперебой ссылаются на Мэта Каттса и говорят, что Гугл использует данные, полученные из тулбара для дополнительного рейтингования результатов поиска. Мэт этого не отрицает, мол, можем и использовать. Конечно могут и конечно используют! Не даром же еще года три назад в тулбаре можно было включить две кнопки-смайлика и голосовать за определенные страницы.
Только использование таких данных на выдачу практически не влияет, поскольку легко накручивается, как, например, зависимость позиции в Яндексе от количества страниц со словом запроса на определенном сайте. В случае с тулбаром достаточно было бы обязать пару сотен секретарш, грузчиков, уборщиц по два три раза давить нужный батон тулбара на страницах корпоративного сайта, а в случае Яндекса нагенерить несколько десятков тысяч страниц на сайте с ключевыми словами. Только стоит ли овчинка выделки?!
Кроме этого везде публикуют новости, что робот AdSense занимается, в качестве подработки, пополнением основного поискового индекса.
Вчера тот же Мэт разъяснил, что на самом деле происходит. Здесь стоит остановиться и рассмотреть подробнее, почему после визита специализированных роботов Google страница может появиться в основной базе.
Кеширование
В протоколе HTTP вопросам кеширования отводится далеко не последняя роль. Вопросы взаимодействия систем кеширования, веб-серверов и HTTP-клиентов (браузеров и роботов) занимают не один раздел соответствующего rfc. Так что кеш — это не только ненавистный сквид, с помощью которого системные администраторы режут такие красивые баннеры и не дают качать mp3 другим обитателям корпоративных сетей. Тот же сквид может работать в качестве веб-акселератора, т.е. располагаться не непосредственно перед пользователем, а сразу за веб-сервером. Я помню свои первые опыты с размещением сайтов на серверах украинских провайдеров, когда счетчик Хотлога давал большее число посетителей, чем серверная статистика. Удивительно, не правда ли?!Молодой GoogleBot и большой папочка
Апдейт «Большой папочка», если можно назвать апдейтом infrastructure switchover, должен минимизировать трафик, как для Google, так и для вебмастеров. Новая версия бота с user-agentMozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
поддерживает сжатие контента в gzip при запросе-передаче, что само по себе позволяет в ряде случаев существенно уменьшать исходящий трафик.
Для экономии трафика также была внедрена система, аналогичная веб-акселератору. Веб-акселератор сам отдает пользователю закешированные данные, если они не изменялась, не заставляя веб-сервер заново собирать страницы с вызовом скриптов и соединениями с базами данных.
Точно также и роботы Гугля пользуются услугами кеша. Если основному роботу требуется некий документ, а этот документ пару часов назад уже притаскивал робот AdSense или робот поиска по блогам, то какой смысл заново запрашивать тот же документ? Никакой.
Вот и пользуются роботы разных сервисов закешированными (сохраненными) копиями документов, а кеш в данном случае используется как промежуточная база, моментальный снимок подмножества страниц сайта. Достаточно внимательно рассмотреть схемы 1 и 2.
{kind=link}
{kind=link}
А со стороны веб-мастера все действительно выглядит так, что робот AdSense занимается пополнением основной поисковой базы.
Написано Cherny в 10:41 PM
March 28, 2006
Обновленный дизайн результатов поиска Google
Последовательность действий, которые надо сделать, чтобы увидеть результаты поиска Google в обновленном виде:
- Зайти на http://www.google.com, причем настаивать именно на com, а не ru или com.ua, куда может перекидывать;
- Удалить куку с именем PREF;
- Скопировать в адресную строку и выполнить следующий код:
- Перезагрузить страницу;
- Попробовать что-нибудь поискать.
Фрагмент результатов поиска в обновленном дизайне можно видеть выше. Мне не нравится!
Написано Cherny в 3:43 PM | Комментариев (2)
March 21, 2006
Изменение спроса по ключевым словам в AdWords
В интрумент подсказки ключевых слов в Google Adwords добавили
новую фичу — тенденцию поиска. Теперь для каждого ключевого слова или словосочетания можно увидеть изменение поискового спроса за последние 12 месяцев, а также явно выводится месяц, когда было самое большое количество запросов.

Написано Cherny в 11:22 AM
March 11, 2006
CL2 или Google Calendar
Бета-версию онлайнового календаря или органайзера от Google тестируют в настоящее время 200 «избранных».

Календарь тесно интегрирован с GMail, используется AJAX и фиды для интеграции с десктоп-календарями, свой календарь можно будет публиковать и давать возможность друзьям добавлять события. Хотя запуск публичной версии еще не скоро.
Некоторое количество скриншотов можно посмотреть здесь.
Написано Cherny в 9:47 AM
February 28, 2006
Google Sitemaps и RSS-потоки
После открытия сервиса по проверке robots.txt в Google SiteMaps решил поподробнее исследовать этот инструмент. Так как устанавливать генератор Sitemap на python — абсолютная авантюра, а писать что-то свое лениво и времени жаль — попытался воспользоваться возможностью добавить RSS-поток вместо карты сайта оригинального формата. Среди поддерживаемых форматов также Atom 0.3 и простой текстовый файл в формате «один URL на строку». RSS 2.0 и Atom 0.3 автоматом создаются в наиболее распространенных блоговых движках.
Ан не тут-то было!
Их обработчик споткнулся обо что-то в RSS-потоке и выдавал ошибку, как для потока текущего блога на Movable Type, так и для моего другого блога на Wordpress. Оказалось, что проблема заключается в конструкции <![CDATA[...]]>, которая не противоречит стандарту, кстати.
RSS-поток на этом блоге я уже подстраивал, чтобы туда попадал весь текст заметок и ссылка на комментарии; убрать конструкцию CDATA оказалось просто — замена 0 на 1 в конфигурационном файле. А вот с движком на Wordpress пришлось поковыряться, не так там все прозрачно, как кажется на первый взгляд. Может я просто квалификацию теряю...
Как бы то ни было, RSS-потоки сейчас парсятся Гуглем без ошибок, так что остается наблюдать за работой SiteMaps.
Написано Cherny в 12:15 PM
February 23, 2006
Google открывает свой narod.ru
Google открывает свой конструктор веб-сайтов — Google Page Creator, позволяющий создавать и редактировать веб-страницы. Интерфейс редактирования страниц простой, позволяет работать со спиcком страниц, редактировать сами страницы, а также загружать файлы других типов. Изображения, кстати, загружаются непосредственно при вставке в страницы.

Но самое интересное заключается в том, что вновь созданные страницы выкладываются на хостинг Google по адресам вида http://yourgmailusername.googlepages.com.
И зачем Гуглю нужна вся эта кухня? Через пару месяцев набегут туда всякие... С другой стороны, никаких намеков на возможность подключаться по FTP не наблюдаю.
Написано Cherny в 12:29 PM | Комментариев (4)
February 8, 2006
Руководство для вебмастеров от Google на русском
В связи с активизацией борьбы Google с международным веб-спамом Мэт Каттс предлагает перечитать руководства для вебмастеров по качеству на их (вебмастеров) родных языках.
Читать, бояться!
Написано Cherny в 10:50 AM | Комментариев (2)
GoogleBot и robots.txt
В дополнение к предыдущей заметке.
Оказывается, что GoogleBot кроме wildcards в robots.txt понимает директиву Allow, мало того:
...and it also permits more specific directives to override more general directives
Интересно девки пляшут! Я тогда тоже хочу таким образом прояснить некоторые вопросы:
to go ask the crawl team to be completely sure
Написано Cherny в 10:33 AM
February 7, 2006
Проверка robots.txt от Google
Google добавил в SiteMaps проверку robots.txt (via)
Danny Sullivan отмечает, что стандарт robots.txt должен быть «более стандартным». В частности, GoogleBot поддерживает символы подстановки * и ?, но не поддерживает директивы Crawl-Delay, которая успешно работает в Yahoo, MSN и Ask.
Кстати, на Crawl-Delay cheker ругается фразой «Syntax not understood», как впрочем и на директиву Host для Яндекса.
А совсем недавно еще всплыла информация о недокументированной фиче Рамблера, который, как оказалось, тоже поддерживает символы подстановки и исключения по подстрокам.
Да уж, стандарт robots.txt, так и не ставший на самом деле стандартом за 12 лет существования, требует существенных дополнений и уточнений, только вот станет ли им проще пользоваться?
Время покажет, скорее всего.
Смотреть также
Расширения в robots.txt
И снова о robots.txt
Обработка Рамблером robots.txt
Написано Cherny в 10:08 AM | Комментариев (2)
February 6, 2006
Самые популярные теги HTML
Переводчикам Вебпланеты посвящается.
Неделю назад Вебпланета описАла масштабное исследование Google популярности различных HTML-тегов, их параметров и прочих вкусностей в более чем миллиарде документов. Все бы хорошо, только вот журналисты-переводчики у Вебпланеты хромают на значительную часть английского алфавита!
Возьмем для примера следующий абзац:
Около 98% всех веб-страниц содержат элементы «head», «html», «title» и «body». Нужно заметить, что три из них являются обязательными элементами HTML-документа. В то же время элемент «title» таковым не является, но все равно встречается в подавляющем большинстве веб-страниц.
А теперь посмотрим как этот же абзац выглядел в оригинале:
Most people (roughly 98%) include head, html, title and body elements. This is somewhat ironic, since three of those four elements are optional in HTML. It's interesting to see that most pages have a title, though.
Что же получается?
Из четырех наиболее встречающихся тегов: html, head, body, title, три — являются необязательными и могут отсутствовать в HTML-документе, а вот title как раз обязательно должен присутствовать! В русскоязычном варианте все получилось с точностью до наоборот.
Дополнительно можно сделать парочку выводов:
- Особое внимание, которое поисковые системы уделяют содержимому заголовку документа, обусловлено значимостью этого тега в рамках стандарта HTML
- Разработчики, верстальщики и прочие веб-рабочие, пропускающие при верстке тег title, тем самым производят на свет документы, которые не соответствуют стандарту HTML. А за это таких людей с чистой совестью следует бить по рукам
- Журналистам и переводчикам вебпланеты учить иностранные языки.
Написано Cherny в 1:13 PM
February 1, 2006
Про 301-й редирект в Google
Возвращаясь к нашим редиректам.
Несколько дней назад в официальном блоге Sitemaps появилась заметка об использовании редиректов при переезде сайта на новый адрес. В заметке сразу несколько ключевых моментов, а информация официальная, прошу заметить.
1. Google сам рекомендует использовать 301-й редирект для переезда сайта на новый адрес в соответствующем разделе помощи.
If your old URLs redirect to your new site using HTTP 301 (permanent) redirects, our crawler will discover the new URLs.
Разделы помощи на поисковых системах должны стоять первыми в списке литературы для специалистов по SEO, кстати!
2. При использовании 301-го редиректа Google не будет считать новые документы дубликатами старых, а будет считать, что старые документы изменили адреса:
Googlebot won't see the new site as duplicate content, but as moved content.
3. Нельзя использовать 302-й редирект, поскольку GoogleBot считает, что переезд временный и надо продолжать работать со старым доменом:
A 302 redirect tells Googlebot that the move is temporary and that Google should continue to index the old domain.
По моим наблюдениям это утверждение справедливо и для отдельных документов...
4. В Google нельзя «руками» выбрать главное зеркало, поскольку процесс индексации полностью автоматизирован:
...we can't manually change your URL in our search results...
и
The crawling and indexing processes are completely automated, so I couldn't tell him exactly when the domain would start showing up in results.
В заключении хочется перефразировать известное утверждение — «Что GoogleBot'у хорошо, то StackRambler'у — смерть». Иначе говоря, использование 301-го редиректа при переезде сайта не является панацеей, следует подходить к вопросу комплексно, использовать все возможные методы: весомые ссылки на новый домен, директиву Host: в robots.txt для Яндекса и т.д.
Написано Cherny в 12:02 PM
January 23, 2006
Новости Google вышли из беты
Google News вышли из беты. Новостной сервис от Google стартовал 23-го сентября 2002 года, т.е. находился в статусе бета более трех лет — 1219 дней, в настоящий момент собирает новости с 4500 новостных источников, по крайней мере так заявлено на странице о сервисе.
Какой сервис следующий на очереди для выхода из беты?
Написано Cherny в 10:45 PM | Комментариев (1)
December 16, 2005
Интервью с Ларри Пейджем в 2038 году
Получите удовольствие от интервью с Ларри Пейджем в 2038!
Там и увольнение Сергея Брина из компании в 2033 году, поглощениее компании Microsoft в 2030, забастовка роботов в 2036...
Больше всего понравилось три вещи:
- Тест Мариссы, когда эксперты рассказывают машине очень грустную историю, если машина начинает плакать, то ей дают человеческие права: возможность платить и т.д.
- Чтобы Гугльботы не индексировали дома, мусорные ведра, письма, открытки, журналы и что-либо еще, просто приклеивайте на них стикер «no index»
- Может ли робот Гугл убить человека?
Написано Cherny в 11:44 AM
December 5, 2005
Архитектура Google
Сегодня на Вебпланете вышла довольно объемная статья «Архитектура Google», где рассматриваются вопросы оборудования датацентров: серверов, стоек, энергообеспечения, а также функционирования систем хранения данных и формирования ответов поисковой системы на пользовательские запросы.
Рекомендуется к прочтению!
Кстати, в марте я писал небольшую заметку о том, как работает Google.
Написано Cherny в 5:38 PM
November 25, 2005
Свежая новость Google Analitics
Пришла сегодня рассылка от Google Analitics, в которой сообщается, что в связи с чрезвычайно высокой нагрузкой временно закрыта возможность добавлять профайлы, то есть ставить на сайты счетчик. Это не удивительно, после многочисленных отзывов, наподобие этого.
После увеличения мощностей «запуск повторится».
Написано Cherny в 12:31 PM
October 24, 2005
Google guys
Список официальных блогов Google, а также персональных блогов его сотрудников.
Написано Cherny в 4:27 PM
September 15, 2005
Об открытии Google Blogsearch :)
Отмечал Сергей Брин с Ильей Сегаловичем День Рождения Ильи, и хвастался Илья, что есть у Яндекса поиск по блогам.
И пришлось Сергею Брину что-то предпринимать в срочном порядке -- так и открылась бета-версия Google Blogsearch на следующий день после Дня Рождения Ильи Сегаловича.
Что ждать от Гугля после Дня Рождения Аркадия Воложа?! :)
Написано Cherny в 4:00 PM | Комментариев (1)
May 30, 2005
А где Google PageRank?
Куда пропал Google PageRank? В баре нет, плагин к FireFox'у пишет на всех unranked. Это временно или решили по примеру Яндекса убрать индикатор?
Написано Cherny в 12:03 PM
April 6, 2005
Google results prefetching
На многих сайтах муссируется новость об интеграции браузеров Mozilla и FireFox с поисковой системой Google. Будем разбираться, как же это работает на самом деле.
Схема работы Search Results Prefetching
При использовании упомянутых браузеров и Google, последний может добавить в код страницы тег <link rel="prefetch" href="http://www.first-result-site.com/">, где www.first-result-site.com — первый сайт в результатах поиска, на который вероятнее всего перейдет пользователь. Почему «может» и «вероятнее всего»? Вот фраза из Google Information for Wemasters:
This tag is only inserted when it is likely that the user will click on the first link.А про то, как определяется это likely ничего не написано! Я уже несколько дней пытаюсь при поиске найти в коде страницы тег <link rel="prefetch">, но не нахожу. Возможно я пользуюсь Гуглем как-то неправильно и в категорию «likely» не попадаю. :)
Ладно, читаем инструкцию дальше. Когда браузер встречает такой тег link, он начинает в бекграунде загружать страницу, указанную в параметре href. При последующем переходе на этот адрес страница будет уже выдаваться из кеша браузера гораздо быстрее.
Как отключить опцию презагрузки написано здесь. Стоит добавить, что страница в бекграунде грузится со всеми куками, изображения не погружаются, насколько я понял. И реферер передается такой же, как будто на страницу зашли из результатов поиска.
Блокирование prefetching со стороны вебмастера
Теперь о том, как вебмастер может блокировать такую презагрузку своих страниц. При запросе страницы в HTTP-запросе передается заголовок X-moz: prefetch, чтобы предотвратить загрузку своих страниц вебмастер может проверять запросы на наличие этого заголовка (в PHP скорее всего будет $_SERVER['HTTP_X_MOZ'], но не факт) и смело выдавать 404 Not Found. Главное по ошибке не выдать 404 роботу Гугля!
А в целом верно заметил euhenio, респект:
Чем больше они напридумывают всякой чертовщины, тем лучше будут жить специалисты по этой чертовщине. :)
Написано Cherny в 4:27 PM
March 18, 2005
Google Code
Открыт Google Code - раздел open source проектов от Google. В XML-формате доступны информация об обновлениях и список приложений, в которых используются Google APIs.
Написано Cherny в 12:23 PM | Комментариев (2)
March 10, 2005
Как работает Google
Известно, что Google использует в своих датацетрах дешевые сервера вместо дорогих 8-ми и более процессорных high-end серверов. Основная фишка – заставить это множество машин работать совместно и исключить ситуации, когда отказ одного сервера может нарушить выполнение операции. Здесь сразу вспоминаются «выпадения кластеров» Яндекса!
В Гугле разработано специальное программное обеспечение для управления серверами. Специальная файловая система Google File System, оптимизированная для работы с 64-х мегабайтными блоками данных, изначально подразумевала сбои оборудования.
Данные сохраняются в трех экземплярах, специальные сервера обеспечивают доступ к копиям, если основные данные недоступны. Кстати, инженеры Гугля обзывают блоки данных shards (черепки, осколки).
Сервера работают под управлением Red Hat Linux, но с переработанным ядром.
Менеджер задач Global Work Queue занимается разделением задач и распределением их по серверам.
Не совсем понял, для чего используется MapReduce . Вроде как для автоматизации восстановления программы после сбоев:
Google's programming tool, called MapReduce, which automates the task of recovering a program in case of a failure, is critical to keeping the company's costs down.
Написано Cherny в 4:45 PM
March 3, 2005
Google Suggest Firefox extension
Плагин к Firefox, позволяющий воспользоваться сервисом Google Suggest непосредственно в поисковом окне браузера.
Сервис при вводе символов в поисковую строку отправляет запрос на сервер Гугля с использованием XMLHttpRequest. Ответ сервера небольшой - около 20Kb, и сжатый, содержит список suggestions. То есть, при вводе каждого символа, браузер и сервер обмениваются небольшой порцией информации.
Написано Cherny в 10:01 AM
February 8, 2005
Google Maps
Google представил свой новый сервис Google Maps. Работает в IE 5.5+ и мозилловских движках, я смотрел Firefox'ом. На сегодняшний день представляет собой глобус Соединенных Штатов Америки.
Написано Cherny в 12:46 PM
February 2, 2005
Google увеличивает лимиты?
Заметка о том, что Google индексирует более 101k на странице, хотя мне повторить результаты поиска не удалось.
Там же несколько других полезных цифр: количество слов в поисковом запросе Гугл недавно увеличил до 32, Yahoo индексирует 150k у HTML-документов и 500k у PDF-документов
Написано Cherny в 10:50 AM
December 11, 2004
Ассоциации в Гугле
...выкатились. Читать здесь и здесь, если вдруг еще не читали.
Написано Cherny в 5:13 PM | Комментариев (3)
November 8, 2004
Google Cheat Sheet
Дополнительные словарные комбинации для Google (via). Я не знал date: и safesearch:. Теперь с помощью оператора date можно отслеживать свежие документы, еще бы по почте приходило :)
Написано Cherny в 9:57 AM