
April 17, 2007
Sitemaps просачивается в robots.txt
Вот сколько раз думал закрыть тему robots.txt, да никак не дадут!
Как многие уже успели отметить, большая западная четверка (Google, Yahoo!, MSN и Ask) приняли протокол Sitemaps, а в рамках протокола механизм Auto-Discovery, позволяющий роботам найти файлы Sitemaps самим, а не ждать сабмита от вебмастеров. Данный механизм подразумевает добавление в robots.txt директивы Sitemap, в значении которой указывается полный путь к файлу, примерно так:
Sitemap: http://webartsolutions.com/sitemap.xml
Эксперты отмечают, что:
Яндексу достаточно включить поддержку Sitemap XML и это станет стандартом де-факто и в Рунете.
Я помню дискуссию Артема Шкондина с сотрудниками Яндекса при добавлении обработки директивы Host, в частности Артем указывал, что данная директива будет непонятной, поскольку указывается главное зеркало, а не запрещаются второстепенные, формат записи приводит сразу к нескольким возможным ошибкам в записи директивы и т.д. Во многих случаях, кстати, ошибки имели место быть.
Представители большой четверки наступили на те же грабли — добавили в robots.txt еще одну неоднозначную директиву. Представим себе, как будет выглядеть запись для Яндекса в robots.txt, если Яндекс добавит поддержку Sitemaps:
User-agent: Yandex
Disallow: /dir/
Disallow: /file.html
Host: webartsolutions.com
Sitemap: http://www.webartsolutions.com/sitemap.xml
Ужасно! Что же оставется делать среднестатистическому вебмастеру? Обращаться к robots.txt-writer'у, скоро появятся такия, знающие особенности применения Allow, Crawl-delay, Host и символов подстановки. К тому времени еще какие-нибудь директивы добавят и оформят версию 2.0 протокола исключений.
Однако, как правильно заметил Филипп, пока нет смысла тратить дополнительное время на создание файла Sitemap, поскольку поисковики и так нормально находят страницы по ссылкам, а в выражении «поисковая оптимизация глубокого веба» маловато смысла.
И напоследок, некоторую мою активность по переводу протокола Sitemap на русский можно считать завершенной, в связи с появлением русскоязычной версии на официальном сайте.
Написано Cherny в 11:11 AM | Комментариев (1) | TrackBack
March 23, 2007
Технологии запрета
Запрещать индексацию некоторых страниц сайта можно, а часто и нужно. Некоторые примеры я рассматривал в своем докладе о robots.txt. За последние пару месяцев в официальных блогах Google вышло несколько постов о стандарте исключений (robots.txt), его дополнений для Гуглбота, ну и результирующий пост со ссылками на все материалы.
А в это же время где-то за границей... Дэнни Салливан публикует подробнейшую инструкцию по мета-тег ROBOTS, варианты его использования и дополнительные параметры, которые понимают разные поисковые системы.
Хотелось бы отдельно остановиться на утверждении, что документ, где указано <meta name="ROBOTS" content="noindex"> все равно будет запрашиваться роботом, хотя бы для того, чтобы прочитать эту инструкцию, а в случае запрета в robots.txt документ(ы) запрашиваться роботом не будут пока запрет фигурирует в файле исключений.
Написано Cherny в 1:24 PM | Комментариев (1)
March 20, 2007
Индексация результатов поиска
Пару недель назад Мэтт Каттс четко ответил на вопрос «Следует ли вебмастерам запрещать индексацию результатов поиска?», в результате изменили и руководство для вебмастеров:
Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don’t add much value for users coming from search engines.
Из фразы ясно, что вебмастер должен использовать правила в robots.txt, с помощью которых запрещать страницы с результатами поиска. В примерах Яндекса явно не указаны результаты поиска, как нежелательный контент, но такие приемы не понравятся модератору, особенно если результаты поиска формируются при помощи Яндекс.XML и на них ставятся статические ссылки. А такими методами в последнее время балуется один из украинских порталов, получающий значительный поисковый трафик именно на результаты поиска.
Еще ссылки по теме:
http://www.seroundtable.com/archives/012671.html
http://searchengineland.com/070312-104201.php
Написано Cherny в 11:10 AM | Комментариев (5)
February 27, 2007
Новые сервисы Google и robots.txt
Многие заинтересованные лица узнавали о новых сервисах Google из его robots.txt, где заранее запрещалась индексация страниц нового сервиса.
Сегодня Филипп Ленссен спрашивает, что такое «rebang», поскольку в файле исключений появилась новая запись: Disallow: /rebang
Написано Cherny в 10:13 AM | Комментариев (0) | TrackBack
December 28, 2006
Непрозвучавший доклад о robots.txt
Вот и подкрался к нам Новый Год! Как и полагается, у меня назрела парочка подарков всем читателям блога, хотя, в первую очередь, себе самому. Итак, подарок номер раз!
На ноябрьской конференции Поисковая оптимизация и продвижение сайтов в интернете я присутствовал в том числе и как докладчик, правда докладчик несколько виртуальный. Я не читал доклад со сцены, поскольку, во-первых, не было сильного желания этого делать, а во-вторых, доклад о такой специфической штуке, как robots.txt, больше половины аудитории просто не восприняла бы. В программе конференции этот доклад также не фигурирует, хотя Михаил Козлов обещал выложить презентация, а вот в сборнике материалов конференции мое произведение есть, так что участники могли там его прочесть.
Сейчас я выложил полный текст доклада, так что встречаем — robots.txt: стандарт, расширения, аспекты применения! А для полноты картины и презентация (392k).
Своим докладом я хотел подвести некоторую черту под вопросами о robots.txt, его формате и применении, тем более некоторое время назад появился неплохой справочный ресурс по robots.txt на русском языке. Есть еще очень много интересных тем для обсуждения и изучения, но об этом чуть позже...
Написано Cherny в 10:48 AM | Комментариев (2)
December 19, 2006
Полное запрещение индексации сайта
Сбылась мечта и... В общем, потребовалось на одном проекте полностью запретить индексацию поисковыми системами, от корня!
Нет ничего проще, две строчки в известном файле были прописаны 7-го декабря:User-agent: *
Disallow: /
Все поисковики ведут себя относительно прогнозируемо. Рамблер, например, проводит проверку запрещающих правил проиндексированным адресам раз в неделю, как правило на выходных, поэтому до выходных можно запрещать Рамблеру любые адреса из ранее проиндексированных и это ни на что не повлияет, они даже будут переиндексироваться, но на выходных карета превратится в тыкву, кони — в мышей, StackRambler сверится с актуальным robots.txt и выкинет все лишнее из базы.
Интересно ведет себя Google. После изменения robots.txt новые адреса, конечно, не индексируются, а уже известные — не переиндексируются заново, однако Гугл прикидывается шлангом и из индекса страницы не удаляет, там лежат сохраненные копии от 5-го декабря и ранее! Более 6 тысяч успешно сохраненных страниц! Хотя для Гугля это скорее правило, буквально на прошлой неделе я имел счастье лицезреть кеш страницы в дополнительном индексе (Supplemental Results) от середины апреля, причем всем роботам было запрещено индексировать страницу где-то в начале мая.
Таким образом Гугл интерпретирует запрещающее правило в robots.txt как запрет индексации и переиндексации, но не как требование удаления уже проиндексированной страницы из индекса.
Написано Cherny в 12:59 AM
November 3, 2006
Yahoo Slurp и robots.txt
Мой (потенциальный) доклад о robots.txt на московскую конференцию устаревает еще до его выхода!
В официальном блоге Yahoo опубликована информация о включении обработки символов подстановки в robots.txt для робота Slurp, в директивах Disallow можно использовать «*» — любые символы, и «$» — завершение строки адреса:
we have just updated Yahoo! Slurp to recognize two additional symbols in the robots.txt directives — "*" and "$".
Есть еще два интересных момента в этом сообщении:
- В качестве имени робота в User-agent используется Yahoo! Slurp, а не просто Slurp, как описано в разделе помощи.
- В примерах кроме всего прочего используется нестандартная директива Allow, которую, опять же, в официальном разделе помощи я не встречал.
Почти в конце заметки подтверждается обработка Allow:
Oh, by the way, if you thought we didn't support the 'Allow' tag, as you can see from these examples, we do.
По-моему, робот Yahoo Slurp теперь поддерживает наибольшее количество нестандартных директив и расширений, включая директиву Crawl-delay.
Написано Cherny в 9:44 AM
September 7, 2006
Ошибка в Google Help
Сегодня нарисовал такой robots.txt на одном сайте, что самому страшно стало. Зато проверим правильность работы основных роботов с документированными и не очень директивами.
Пока рисовал, натолкнулся в одном из разделов помощи Гугля на ошибку:
Для блокирования доступа ко всем URL, включающим вопросительный знак (?), можно использовать следующую запись:User-Agent: *
Allow: /*?*
Эта запись как раз позволит роботу Гугля индексировать все странице с вопросительными знаками в адресе, а не заблокирует. Ошибка повторяется в английском варианте тоже.
Если такую запись поместить в реальный robots.txt, то, по идее, на ней споткнутся все роботы, кроме Google: либо запись будет проигнорирована полностью, либо проигнорирована строка с Allow как не соответствующая стандарту. А поскольку ни одной строки с Disallow не наблюдается, то вся запись проигнорируется в любом случае. Я уже как-то писал, но повторюсь: нестандартные директивы следует применять только в собственной секции понимающего их робота.
Написано Cherny в 11:05 PM
August 15, 2006
Приоритеты обработки записей в robots.txt
Как много девушек хороших, а нас все тянет на плохих
Barry Schwartz дает ссылки на обсуждения приоритета выбора записей в robots.txt роботами поисковых систем.
Меня всегда удивляло, как можно делать такие разные и вычурные ошибки в таком простом файле исключений с четким и однозначным форматом? Можно, конечно, грешить на большое количество расширений, которые добавляет в стандарт каждая значимая система с широко известными в узких кругах именами роботов: Google, Yahoo, MSN, Yandex. Но в таком случае и вопросы по robots.txt возникали бы прежде всего именно по расширениям.
Вернемся к приоритетам. Как известно, записи в robots.txt разделяются пустыми строками, каждая запись — это инструкция для одного или нескольких роботов. Пусть мы имеем следующее содержание файла исключений:
User-agent: *
Disallow: /dir/file
User-agent: Yandex
Disallow: /reports
User-agent: Googlebot
Disallow: /users
Allow: /best-page.html
Вопрос заключался в том, какими директивами в данном случае будет руководствоваться робот Гугля, что для него будет запрещено? Можно подумать, что робот наткнется в первую очередь на секцию для всех роботов и именно ее правила примет к рассмотрению. Это неверное предположение. Робот при парсинге файла работает примерно по следующему алгоритму:
- Получает полностью файл
- Выделяет в файле корректные секции
- Ищет "свою" секцию
- Если своя секция найдена принимает к руководству ее инструкции.
- Если своей секции не обнаружено, ищет секцию для всех роботов
- Если обнаружена секция для всех роботов, принимает к руководству ее инструкции
- Если общая секция не найдена, робот считает, что индексировать можно все без исключения.
Отсюда делаем сразу несколько выводов:
- Порядок секций в файле значения не имеет.
- Если будет найдена "своя секция", то робот будет руководствоваться только ее инструкциями, игнорируя все остальные, поэтому в нашем примере робот Гугл абсолютно справедливо будет индексировать /dir/file.
- Отсутствие общей секции — разрешение индексировать весь сайт роботам, не упомянутым ни в одной секции.
Пора писать свой сервис проверки, но это ж сколько кодировать надо!
Написано Cherny в 10:58 PM | Комментариев (13)
August 8, 2006
GWC - продолжение
Кроме самого сервиса, старый блог тоже переехал на новый адрес.
Остановлюсь подробнее на «фичах» Google Webmaster Central.
Изменения интерфейса
Сам интерфейс претерпел изменения. Более удобно стало просматривать информацию об индексировании, URL, запрещенные для индексации и т.д. На скриншоте я обвел ссылку на новый инструмент по указанию основного зеркала
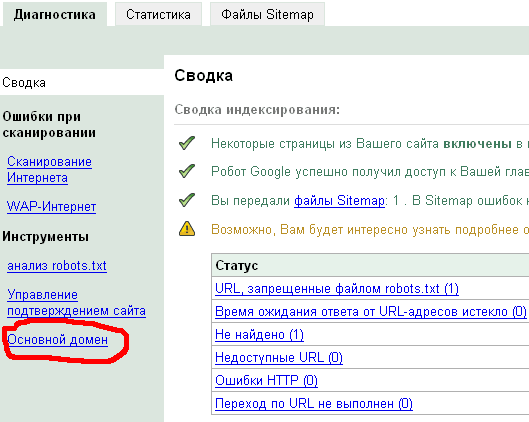
Выбор основного зеркала сайта
Вот как выглядит форма выбора основного адреса для домена — с www или без.

Выбор скорости индексации сайта
Форма выбора скорости индексации сайта в данный момент тестируется и показывается только малому количеству вебмастеров. У меня ссылки на нее нет, скриншот взял отсюда.
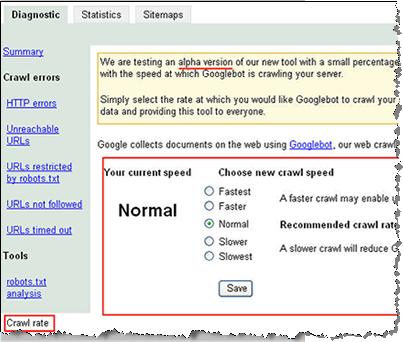
Статистика индексации самого Google
На следующем скриншоте из блога GWC можно рассмотреть статистику индексации Гуглом самого себя:
- HTTP-ошибок: 34
- Не найдено: 13617
- URL time out: 6
- Недоступных адресов: 1151
- Запрещено в robots.txt: 1493507

Написано Cherny в 9:20 AM | Комментариев (1)
June 22, 2006
Google добавляет в хелп секцию о robots.txt
Неделю назад в раздел Как Google сканирует мой сайт справки для вебмастеров добавлена секция Использование файла robots.txt, в частности такие вопросы как:
- Как создать файл robots.txt?
- Список различных агентов Google для строк User-agent, тут же описывается директива Allow, которая исключительно в Гугле и работает
- Использование шаблонов (символов подстановки), опять же, только в Гугл
- Как часто перезапрашивается robots.txt - раз в день
Хотя в некоторые статьи, так сказать, засрались очепятки. А именно в примерах следует отделять записи для разных роботов пустой строкой, как это записано в англоязычной версии этой же страницы. А вот в немецкой, испанской, русской и других версиях пустой строки не обнаруживается. Так что документацию следует читать на языке оригинала или периодически с оригиналом сверяться.
Неделю назад также появилось сообщение, что форма проверки robots.txt в Google Sitemaps выдает ошибку, если объем файла превышает 5000 символов. Это может быть как особенностью реализации формы проверки, так и оограничением робота при обработке файла исключений. Мне сложно представить даже довольно большой сайт, для которого надо писать почти 5-ти килобайтный robots.txt, это ж сколько всего запретного сгенерить надо! :)
Написано Cherny в 3:30 PM
February 13, 2006
Запрет индексации картинок
Довольно просто можно найти имена агентов, которые собирают изображения для поиска по картинкам Google и Yahoo, это Googlebot-Image и Yahoo-MMCrawler.
Соответственно, для того, чтобы спровадить с сайта картиночных роботов, достаточно в robots.txt создать отдельную секцию:
User-agent: Googlebot-Image
User-agent: Yahoo-MMCrawler
Disallow: /
А как аналогично указать в robots.txt картиночного робота Яндекса, который в логах представляется как Yandex/1.01.001 (compatible; Win16; P)?
Написано Cherny в 10:53 AM | Комментариев (7)
February 8, 2006
GoogleBot и robots.txt
В дополнение к предыдущей заметке.
Оказывается, что GoogleBot кроме wildcards в robots.txt понимает директиву Allow, мало того:
...and it also permits more specific directives to override more general directives
Интересно девки пляшут! Я тогда тоже хочу таким образом прояснить некоторые вопросы:
to go ask the crawl team to be completely sure
Написано Cherny в 10:33 AM
February 7, 2006
Проверка robots.txt от Google
Google добавил в SiteMaps проверку robots.txt (via)
Danny Sullivan отмечает, что стандарт robots.txt должен быть «более стандартным». В частности, GoogleBot поддерживает символы подстановки * и ?, но не поддерживает директивы Crawl-Delay, которая успешно работает в Yahoo, MSN и Ask.
Кстати, на Crawl-Delay cheker ругается фразой «Syntax not understood», как впрочем и на директиву Host для Яндекса.
А совсем недавно еще всплыла информация о недокументированной фиче Рамблера, который, как оказалось, тоже поддерживает символы подстановки и исключения по подстрокам.
Да уж, стандарт robots.txt, так и не ставший на самом деле стандартом за 12 лет существования, требует существенных дополнений и уточнений, только вот станет ли им проще пользоваться?
Время покажет, скорее всего.
Смотреть также
Расширения в robots.txt
И снова о robots.txt
Обработка Рамблером robots.txt
Написано Cherny в 10:08 AM | Комментариев (2)
July 18, 2005
И снова о robots.txt
Казалось бы, что еще можно сказать, если есть стандарт 94(!) года всего с несколькими простыми правилами. 11 лет для веба — огромный срок, можно разобраться со всеми проблемными вопросами и пользоваться с закрытыми глазами. Ан нет! Придумали добавлять расширения в robots.txt, чтобы решать какие-то дополнительные задачи. Теперь роботы одной SE путаются в расширениях для другой SE.
Недавно подняли интересную тему, где указали на явную ошибку в разделе помощи Яндекса, посвященному зеркалам, а именно: для каждой записи в robots.txt обязательно хотя бы одна строка с Disallow:, поэтому следующий пример кода нарушает стандарт:
User-Agent: *
Host: www.myhost.ru
Хотя в процессе обсуждения обнаружилось, что сам стандарт не лишен своих «косяков». Так, в разделе The Format первый раз в документе встречается термин «header», причем в предложении Unrecognised headers are ignored. Сотрудники Яндекса трактуют этот термин, как «строка» или «отдельная директива» в пределах записи (record), тогда использование директивы Host: в секции для всех роботов правомерно и не должно вызывать проблем. Однако сотрудники Google, видимо, трактовали термин «header» как запись, соответственно, GoogleBot полагает всю запись с директивой Host: неверно оформленной и игнорирует ее полностью!
Отсюда делаем вывод и оформляем его, как дополнительное неофициальное правило составления robots.txt:
Дополнительные директивы следует применять только в записях (секциях) для роботов, поддерживающих данные директивы.
Или по другому:
Не использовать дополнительные директивы в секции для всех роботов.
Т.е. никаких Host: или Crawl-delay: в секции User-agent: *
P.S. Замечание о том, что webmaster.yandex.ru использует устаревшую базу зеркал следует считать дополнительным бонусом. :)
Написано Cherny в 9:30 AM | Комментариев (1)
January 14, 2005
Яндекс и robots.txt
В продолжение темы о поле Accept в заголовке запроса файла robots.txt индексатором Яндекса. Проверил - при обращении к robots.txt у индексатора Яндекса в запросе просто отсутствует поле Accept! Что оправдано, поскольку в стандарте отсутствуют требования или рекомендации о том, какого типа должны быть данные. Объясняется только, почему именно такое название дали файлу исключений.
Таким образом, "проблема ошибки 406" может возникать только для контента сайта, но не для файла исключений, если он существует. Так что если Яндекс не индексирует, дополнительно стоит проверять отклик сервера при запросах документов только определенных типов, о чем уже неоднократно писалось.
Написано Cherny в 9:38 AM
December 21, 2004
Обработка Рамблером robots.txt
Механизм Рамблера по обработке robots.txt работает по следующей схеме: раз в неделю на выходных берет файл и сверяется, какие из документов сайта, присутствующих в базе, попадают под правила запрещения индексации. Такие страницы из базы сразу удаляются. Таким образом не надо ждать, когда дойдет очередь до переиндексации запрещенных страниц, как в Яндексе.
Подсунул Яндексу правило Disallow: /?, чтобы проверить, не обрабатывает ли механизм знак вопроса как символ подстановки. Все отработало правильно - никаких подстановок, иначе бы весь сайт из базы вывалился.
Написано Cherny в 2:36 PM | Комментариев (2)
November 14, 2004
Полезность перечитывания manuals поисковиков
Euhenio перечитывает доки Рамблера. Где-то месяц назад, перечитывая доки Яндекса, я был несколько удивлен, когда оказалось, что пробел между словами - это логическое И только в пределах предложения, поиск с применением оператора логического И в пределах документа (слово1 && слово2) дает иногда совсем другие результаты.
Написано Cherny в 9:16 PM
October 5, 2004
Расширения в robots.txt
Все-таки полезно иногда читать инструкции. Оказывется Yahoo поддерживает свое расширение в robots.txt. Дополнительная инструкция Crawl-delay определяет время в секундах между успешными запросами документов с сайта роботом Slurp.
Таким образом, каждая поисковая система решает свои проблемы с помощью инструкций в robots.txt: Яндекс решает проблему с зеркалами, Google позволяет использовать символы подстановки в Disallow, а Yahoo - ограничивать нагрузку на сервер. У кого что болит...
Осталось еще Рамблеру придумать свое расширение, только у них и стандартный robots.txt не всегда правильно разбирается, скорее всего из-за wildcards. Кстати, небольшой эксперимент нарисовался.
Написано Cherny в 11:48 AM