
August 31, 2007
В Yahoo "улучшили" работу Slurp...
На прошлой неделе в Yahoo официально заявили об улучшении алгоритма работы поискового робота Slurp, в процессе тестирования и апдейта робота "отпустили погулять", в результате на многих сайтах от него увеличилось количество запросов и, соответственно, трафик. В Yahoo заявляют, что в будущем подобного больше не повторится, поскольку введены новые ограничения:
Don't fret, though, if you're concerned about seeing an increased load. We've initiated efforts and established policies internally to ensure this doesn't happen, even temporarily, in the future.
Западные вебмастера недовольны такими "улучшениями" и указывают на необходимость использования роботами общего кеша:
The fact that Yahoo has multiple crawlers for every division that crawl independently and don't share the common cache, now THAT's a problem that needs to be fixed.
Роботы Гугля, например, общий кеш используют, я об этом писал.
На просторах Рунета от Yahoo пользы практически никакой, а трафик, потребляемый роботом Slurp, как-никак зарубежный. На их внутренние ограничения надеяться не стоит, тем более вебмастер сам может их робота ограничить - параметр Crawl-Delay в robots.txt и можно спать спокойно.
Написано Cherny в 10:15 AM | Комментариев (0) | TrackBack
April 17, 2007
Sitemaps просачивается в robots.txt
Вот сколько раз думал закрыть тему robots.txt, да никак не дадут!
Как многие уже успели отметить, большая западная четверка (Google, Yahoo!, MSN и Ask) приняли протокол Sitemaps, а в рамках протокола механизм Auto-Discovery, позволяющий роботам найти файлы Sitemaps самим, а не ждать сабмита от вебмастеров. Данный механизм подразумевает добавление в robots.txt директивы Sitemap, в значении которой указывается полный путь к файлу, примерно так:
Sitemap: http://webartsolutions.com/sitemap.xml
Эксперты отмечают, что:
Яндексу достаточно включить поддержку Sitemap XML и это станет стандартом де-факто и в Рунете.
Я помню дискуссию Артема Шкондина с сотрудниками Яндекса при добавлении обработки директивы Host, в частности Артем указывал, что данная директива будет непонятной, поскольку указывается главное зеркало, а не запрещаются второстепенные, формат записи приводит сразу к нескольким возможным ошибкам в записи директивы и т.д. Во многих случаях, кстати, ошибки имели место быть.
Представители большой четверки наступили на те же грабли — добавили в robots.txt еще одну неоднозначную директиву. Представим себе, как будет выглядеть запись для Яндекса в robots.txt, если Яндекс добавит поддержку Sitemaps:
User-agent: Yandex
Disallow: /dir/
Disallow: /file.html
Host: webartsolutions.com
Sitemap: http://www.webartsolutions.com/sitemap.xml
Ужасно! Что же оставется делать среднестатистическому вебмастеру? Обращаться к robots.txt-writer'у, скоро появятся такия, знающие особенности применения Allow, Crawl-delay, Host и символов подстановки. К тому времени еще какие-нибудь директивы добавят и оформят версию 2.0 протокола исключений.
Однако, как правильно заметил Филипп, пока нет смысла тратить дополнительное время на создание файла Sitemap, поскольку поисковики и так нормально находят страницы по ссылкам, а в выражении «поисковая оптимизация глубокого веба» маловато смысла.
И напоследок, некоторую мою активность по переводу протокола Sitemap на русский можно считать завершенной, в связи с появлением русскоязычной версии на официальном сайте.
Написано Cherny в 11:11 AM | Комментариев (1) | TrackBack
March 23, 2007
Технологии запрета
Запрещать индексацию некоторых страниц сайта можно, а часто и нужно. Некоторые примеры я рассматривал в своем докладе о robots.txt. За последние пару месяцев в официальных блогах Google вышло несколько постов о стандарте исключений (robots.txt), его дополнений для Гуглбота, ну и результирующий пост со ссылками на все материалы.
А в это же время где-то за границей... Дэнни Салливан публикует подробнейшую инструкцию по мета-тег ROBOTS, варианты его использования и дополнительные параметры, которые понимают разные поисковые системы.
Хотелось бы отдельно остановиться на утверждении, что документ, где указано <meta name="ROBOTS" content="noindex"> все равно будет запрашиваться роботом, хотя бы для того, чтобы прочитать эту инструкцию, а в случае запрета в robots.txt документ(ы) запрашиваться роботом не будут пока запрет фигурирует в файле исключений.
Написано Cherny в 1:24 PM | Комментариев (1)
December 28, 2006
Непрозвучавший доклад о robots.txt
Вот и подкрался к нам Новый Год! Как и полагается, у меня назрела парочка подарков всем читателям блога, хотя, в первую очередь, себе самому. Итак, подарок номер раз!
На ноябрьской конференции Поисковая оптимизация и продвижение сайтов в интернете я присутствовал в том числе и как докладчик, правда докладчик несколько виртуальный. Я не читал доклад со сцены, поскольку, во-первых, не было сильного желания этого делать, а во-вторых, доклад о такой специфической штуке, как robots.txt, больше половины аудитории просто не восприняла бы. В программе конференции этот доклад также не фигурирует, хотя Михаил Козлов обещал выложить презентация, а вот в сборнике материалов конференции мое произведение есть, так что участники могли там его прочесть.
Сейчас я выложил полный текст доклада, так что встречаем — robots.txt: стандарт, расширения, аспекты применения! А для полноты картины и презентация (392k).
Своим докладом я хотел подвести некоторую черту под вопросами о robots.txt, его формате и применении, тем более некоторое время назад появился неплохой справочный ресурс по robots.txt на русском языке. Есть еще очень много интересных тем для обсуждения и изучения, но об этом чуть позже...
Написано Cherny в 10:48 AM | Комментариев (2)
December 14, 2006
Индексация и GoogleBar
Насколько я помню, пару лет назад существовало несколько базовых оптимизаторских заповедей, что-то вроде guideline. Среди прочего в этих ответах было утверждение, что Гугл не добавляет новые страницы в очередь на индексацию при помощи своего тулбара. На днях появились подробности о недавнем споре немецкого блоггера Филиппа Ленссена и сотрудника Google Мэтта Каттса о возможности индексации страниц при помощи тулбара.
Филипп предположил, что страницы могут индексироваться, поскольку для отображения в тулбаре значения PageRank в Гугл отправляется специальный запрос, в котором фигурирует адрес страницы. В случае отсутствия такого адреса в индексе, вполне возможно сразу же поставить его в очередь на индексацию:
it might be possible the Atom feed is now indexed via e.g. the Google Toolbar (which is known to get pages into the Google index even when those pages are unlinked)
...Google knows the URL of every page you visit if you enable the Google Toolbar advanced options, as it will send the URL to Google to check for the URL's PageRank. It was my understanding this also gets the page indexed
Мэтт там же ответил, что такое навряд ли возможно и попросил дать знать, если эта гипотеза подтвердится:
I don't believe that part in parentheses is true; let me know if you've got a source for that and I'll go and comment there..
В результате Филипп поставил несложный эксперимент: разместил у себя на сайте страницу с уникальным текстом, на которую не было внешних ссылок, после чего заходил на эту страницу браузером с установленным тулбаром просто набирая URL в адресной строке. Страница была создана в августе и до сего момента не находится по уникальному запросу.
В результате эксперимента было подтверждено, что страницы без каких-либо входящих ссылок не попадают в индекс Google только благодаря их открытию в браузере с гугл баром.
В обсуждении эксперимента всплыл еще один интересный вопрос: человек воспользовался стандартной формой добавления, но добавленная страница так и не появилась в индексе. Мэтт заметил, что они не гарантируют попадание в индекс страниц, адреса которых были получены с помощью формы добавления. Хотя сенсации из этого факта делать не стоит, я сталкивался с особенностями добавления страниц в индекс Google еще 6 лет назад, когда только начинал постигать азы, а тогда и деревья были выше, и трава зеленее, и роботы медленнее, и апдейты реже...
Я повторю эксперимент по включению в индекс страниц с помощью тулбаров, правда с некоторыми корректировками, тем более что есть еще один известный тулбар, с участием которого в индексации уже довелось сталкиваться! :)
Написано Cherny в 2:01 AM
November 3, 2006
Yahoo Slurp и robots.txt
Мой (потенциальный) доклад о robots.txt на московскую конференцию устаревает еще до его выхода!
В официальном блоге Yahoo опубликована информация о включении обработки символов подстановки в robots.txt для робота Slurp, в директивах Disallow можно использовать «*» — любые символы, и «$» — завершение строки адреса:
we have just updated Yahoo! Slurp to recognize two additional symbols in the robots.txt directives — "*" and "$".
Есть еще два интересных момента в этом сообщении:
- В качестве имени робота в User-agent используется Yahoo! Slurp, а не просто Slurp, как описано в разделе помощи.
- В примерах кроме всего прочего используется нестандартная директива Allow, которую, опять же, в официальном разделе помощи я не встречал.
Почти в конце заметки подтверждается обработка Allow:
Oh, by the way, if you thought we didn't support the 'Allow' tag, as you can see from these examples, we do.
По-моему, робот Yahoo Slurp теперь поддерживает наибольшее количество нестандартных директив и расширений, включая директиву Crawl-delay.
Написано Cherny в 9:44 AM
September 25, 2006
Роботы Гугл становятся российскими интернет-пользователями
Для сайтов, размещенных на мастерхосте, трафик, сгенерированный роботами Гугл, будет считаться российским, а не зарубежным.
Теперь можно не разбираться с ходом индексации сайтов со сложной структурой и не закрывать от индексации малоинформативные страницы, поменьше станет вопросов о том, что роботы слишком нагружают сайт. Хотя нет, нагружать будут так же, только уже почти свои, а со своими и разговор другой!
Написано Cherny в 10:04 PM
August 29, 2006
Google Wireless Transcoder
Несмотря на большое количество различных лог-анализаторов и сервисов обсчета статистики, в том числе и заточенных под SEO, стоит иногда просто проглядывать логи.
Вот, например, выловился интересный зверь Google Wireless Transcoder. robots.txt он не запрашивает, никакого поясняющего URL в User-agent не указано.
Оказывается это специальный агент Google, подготавливающий контент для мобильников, причем не сканирующий, а именно преобразующий, не зря упоминается Transcoder.
Из особенностей поведения следует отметить несколько запросов графики с пустыми полями Referer и User-agent с того же IP. То есть забирается вся страница с графикой и преобразуется на лету, но при этом JavaScript не исполняется. CSS-ом тоже не интересуется.
Полный User-agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; Google Wireless Transcoder;)
Таким образом можно отловить читателей через мобильные устройства, нашедших контент в Гугле, только вот поискового запроса нет.
Написано Cherny в 12:47 AM
August 8, 2006
GWC - продолжение
Кроме самого сервиса, старый блог тоже переехал на новый адрес.
Остановлюсь подробнее на «фичах» Google Webmaster Central.
Изменения интерфейса
Сам интерфейс претерпел изменения. Более удобно стало просматривать информацию об индексировании, URL, запрещенные для индексации и т.д. На скриншоте я обвел ссылку на новый инструмент по указанию основного зеркала
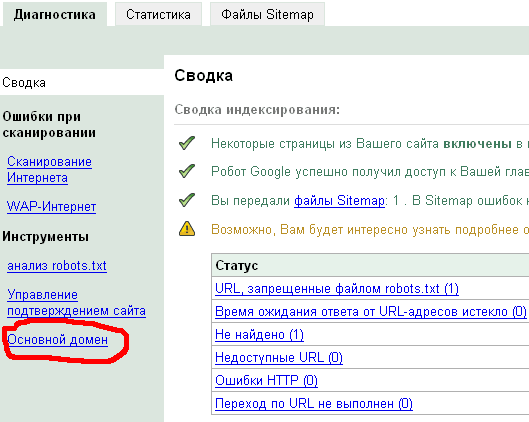
Выбор основного зеркала сайта
Вот как выглядит форма выбора основного адреса для домена — с www или без.

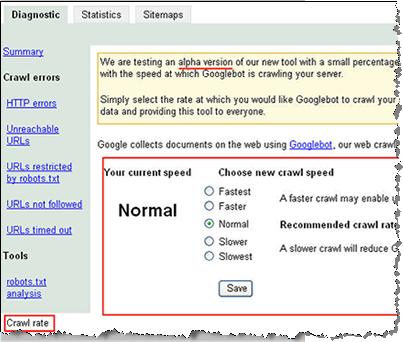
Выбор скорости индексации сайта
Форма выбора скорости индексации сайта в данный момент тестируется и показывается только малому количеству вебмастеров. У меня ссылки на нее нет, скриншот взял отсюда.
Статистика индексации самого Google
На следующем скриншоте из блога GWC можно рассмотреть статистику индексации Гуглом самого себя:
- HTTP-ошибок: 34
- Не найдено: 13617
- URL time out: 6
- Недоступных адресов: 1151
- Запрещено в robots.txt: 1493507

Написано Cherny в 9:20 AM | Комментариев (1)
August 2, 2006
msnbot переименовали
Робота поисковой системы от Майкрософт переименовали, вернее отпочковали от него узкоспециализированных агентов, в частности:
msnbot-products — бот «Shopping», не знаю очем речь, подскажите, кто в курсе;
msnbot-news — новостной робот;
msnbot-media — робот поиска по изображениям, теперь можно для экономии запретить индексацию сайта роботу для картинок, но открыть всем остальным;
msnbot — робот для основного поиска.
Написано Cherny в 12:05 AM
July 31, 2006
Yahoo Slurp обновился
Официальный блог Yahoo сообщает о выходе новой версии поискового робота Slurp. Обещают снижение трафика до 25% без снижения индексации.
Yahoo Slurp и раньше отличался изрядной прожорливостью, а в последние недели оба робота работали практически параллельно, потребляя больше трафика.
Интересно, какими методами будет достигаться заявленное повышение качества индексации? Заголовок If Not Modified Slurp давно использует, может будут использовать несколько запросов в пределах одного HTTP-соединения, раньше вроде бы такого за ним не замечалось, в отличие от GoogleBot, с которым даже очень показательный баг приключился. Только как же быть с дополнительной директиве Crawl-Delay в robots.txt которая ограничивает время между двумя запросами робота к сайту? Неужели тут-то вся оптимизация и накроется?
Написано Cherny в 11:23 PM
July 17, 2006
Описанию из ODP - нет!
В Google добавили обработку еще одного дополнительного метатега, чтобы в результатах поиска не использовалось описание сайта в ODP в качестве сниппета. Для на страницах сайта надо использовать один из вариантов:
<META NAME="ROBOTS" CONTENT="NOODP">
<META NAME="GOOGLEBOT" CONTENT="NOODP">
Некоторые шутят, что надо еще добавить обработку таких тегов, как:
<META NAME="GOOGLEBOT" CONTENT="NOBAN">
<META NAME="GOOGLEBOT" CONTENT="AlwaysFirstResult">
Написано Cherny в 10:35 AM | Комментариев (1)
May 15, 2006
GoogleBot воспользовался дырой в настройках веб-сервера
На прошлой неделе главный борец с веб-спамом в Google, еще до того, как представили Google Trends и Google Co-op описал довольно интересный случай из жизни GoogleBot и crawl/index team, проще говоря робототехников.
Суть вопроса заключалась в том, что Google показывал контент с одного сайта (А) под адресом другого (Б), причем и А, и Б висели на одном сервере (IP) как виртуальные хосты. Причем ни Yahoo, ни MSN таких вольностей себе не позволяли. Пришлось робототехникам разбираться, что же на самом деле творилось в процессе краулинга/индексации. Смоделировать ситуацию удалось с помощью telnet, оказалось, что проблема заключалась в неправильной настройке виртуальных хостов.
GoogleBot при индексации использует возможность протокола HTTP 1.1 не разрывать соединения после получения каждого документа, а получить несколько документов за один присест. Кто изучал серверные заголовки — копать в сторону Keep-Alive. Эту фичу внедрили как раз в версии 1.1 для того, чтобы можно было получить в пределах одного соединения не только саму веб-страницу, но и файл стилей и картинок как можно больше.
Вот и получилось, что сервер навыдавал роботу Гугля документов из разных виртуальных хостов в пределах одного соединения. Робот, конечно, very smart, в результате.
Кстати, о птичках! Для Supplemental Results (Дополнительных Результатов) не только база своя, но и робот отдельно-индексирующий?
Написано Cherny в 11:40 PM
April 25, 2006
Google: кеширование при индексировании
А в это время где-то за границей...
Владимир Путин: мы цены на газ для Украины не из носа выковыривали.
Украинская правда: В. Путин выковыривал цены на газ не из носа
Все наперебой ссылаются на Мэта Каттса и говорят, что Гугл использует данные, полученные из тулбара для дополнительного рейтингования результатов поиска. Мэт этого не отрицает, мол, можем и использовать. Конечно могут и конечно используют! Не даром же еще года три назад в тулбаре можно было включить две кнопки-смайлика и голосовать за определенные страницы.
Только использование таких данных на выдачу практически не влияет, поскольку легко накручивается, как, например, зависимость позиции в Яндексе от количества страниц со словом запроса на определенном сайте. В случае с тулбаром достаточно было бы обязать пару сотен секретарш, грузчиков, уборщиц по два три раза давить нужный батон тулбара на страницах корпоративного сайта, а в случае Яндекса нагенерить несколько десятков тысяч страниц на сайте с ключевыми словами. Только стоит ли овчинка выделки?!
Кроме этого везде публикуют новости, что робот AdSense занимается, в качестве подработки, пополнением основного поискового индекса.
Вчера тот же Мэт разъяснил, что на самом деле происходит. Здесь стоит остановиться и рассмотреть подробнее, почему после визита специализированных роботов Google страница может появиться в основной базе.
Кеширование
В протоколе HTTP вопросам кеширования отводится далеко не последняя роль. Вопросы взаимодействия систем кеширования, веб-серверов и HTTP-клиентов (браузеров и роботов) занимают не один раздел соответствующего rfc. Так что кеш — это не только ненавистный сквид, с помощью которого системные администраторы режут такие красивые баннеры и не дают качать mp3 другим обитателям корпоративных сетей. Тот же сквид может работать в качестве веб-акселератора, т.е. располагаться не непосредственно перед пользователем, а сразу за веб-сервером. Я помню свои первые опыты с размещением сайтов на серверах украинских провайдеров, когда счетчик Хотлога давал большее число посетителей, чем серверная статистика. Удивительно, не правда ли?!Молодой GoogleBot и большой папочка
Апдейт «Большой папочка», если можно назвать апдейтом infrastructure switchover, должен минимизировать трафик, как для Google, так и для вебмастеров. Новая версия бота с user-agentMozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
поддерживает сжатие контента в gzip при запросе-передаче, что само по себе позволяет в ряде случаев существенно уменьшать исходящий трафик.
Для экономии трафика также была внедрена система, аналогичная веб-акселератору. Веб-акселератор сам отдает пользователю закешированные данные, если они не изменялась, не заставляя веб-сервер заново собирать страницы с вызовом скриптов и соединениями с базами данных.
Точно также и роботы Гугля пользуются услугами кеша. Если основному роботу требуется некий документ, а этот документ пару часов назад уже притаскивал робот AdSense или робот поиска по блогам, то какой смысл заново запрашивать тот же документ? Никакой.
Вот и пользуются роботы разных сервисов закешированными (сохраненными) копиями документов, а кеш в данном случае используется как промежуточная база, моментальный снимок подмножества страниц сайта. Достаточно внимательно рассмотреть схемы 1 и 2.
{kind=link}
{kind=link}
А со стороны веб-мастера все действительно выглядит так, что робот AdSense занимается пополнением основной поисковой базы.
Написано Cherny в 10:41 PM
February 13, 2006
Запрет индексации картинок
Довольно просто можно найти имена агентов, которые собирают изображения для поиска по картинкам Google и Yahoo, это Googlebot-Image и Yahoo-MMCrawler.
Соответственно, для того, чтобы спровадить с сайта картиночных роботов, достаточно в robots.txt создать отдельную секцию:
User-agent: Googlebot-Image
User-agent: Yahoo-MMCrawler
Disallow: /
А как аналогично указать в robots.txt картиночного робота Яндекса, который в логах представляется как Yandex/1.01.001 (compatible; Win16; P)?
Написано Cherny в 10:53 AM | Комментариев (7)
February 1, 2006
Про 301-й редирект в Google
Возвращаясь к нашим редиректам.
Несколько дней назад в официальном блоге Sitemaps появилась заметка об использовании редиректов при переезде сайта на новый адрес. В заметке сразу несколько ключевых моментов, а информация официальная, прошу заметить.
1. Google сам рекомендует использовать 301-й редирект для переезда сайта на новый адрес в соответствующем разделе помощи.
If your old URLs redirect to your new site using HTTP 301 (permanent) redirects, our crawler will discover the new URLs.
Разделы помощи на поисковых системах должны стоять первыми в списке литературы для специалистов по SEO, кстати!
2. При использовании 301-го редиректа Google не будет считать новые документы дубликатами старых, а будет считать, что старые документы изменили адреса:
Googlebot won't see the new site as duplicate content, but as moved content.
3. Нельзя использовать 302-й редирект, поскольку GoogleBot считает, что переезд временный и надо продолжать работать со старым доменом:
A 302 redirect tells Googlebot that the move is temporary and that Google should continue to index the old domain.
По моим наблюдениям это утверждение справедливо и для отдельных документов...
4. В Google нельзя «руками» выбрать главное зеркало, поскольку процесс индексации полностью автоматизирован:
...we can't manually change your URL in our search results...
и
The crawling and indexing processes are completely automated, so I couldn't tell him exactly when the domain would start showing up in results.
В заключении хочется перефразировать известное утверждение — «Что GoogleBot'у хорошо, то StackRambler'у — смерть». Иначе говоря, использование 301-го редиректа при переезде сайта не является панацеей, следует подходить к вопросу комплексно, использовать все возможные методы: весомые ссылки на новый домен, директиву Host: в robots.txt для Яндекса и т.д.
Написано Cherny в 12:02 PM
December 27, 2005
Стишки
Я не буду подводить итоги уходящего года, поскольку все было хорошо, и не буду делать предсказания на следующий год, поскольку все будет еще лучше!
Я просто начну поздравлять всех с наступающим Новым Годом!
А для затравки стишки:
Тихо в сети, только не спит GoogleBot.
Список URL’ов получил GoogleBot,
вот и не спит GoogleBot.
Тихо в сети, только Yandex не спит –
Быстро страницы порталов шерстит,
Вот и не спит.
Тихо в сети, только StackRambler не спит,
Запутался в сессиях Rambler, бандит,
Вот и не спит.
Тихо в сети, BigmirSpider не спит,
Сегодня UA он индексит,
Вот и не спит.
Написано Cherny в 7:07 PM | Комментариев (1)
December 13, 2005
Alexa открывает разработчикам индекс
Alexa Web Search открывает разработчикам поисковый индекс, который собирался и обновлялся с 1996-го года роботом ia_archiver. (via).
Как они пишут: теперь каждый может создать новые поисковые сервисы без инвестирования миллионов долларов в индексацию, хранение и обработку данных, серверные технологии.
Три «снимка» под 100 терабайт каждый. Просто так не качнешь!
Написано Cherny в 9:53 AM
August 19, 2005
Yandex Dyatel
Александр Садовский на форуме указал на изменения в разделе нового FAQ, где расписано, чем занимаются недавно замеченные роботы Dyatel от Яндекса — это не более чем «простукивалки» доступности ресурса.
Буква в User-Agent определяет специализацию дятла:
C — Яндекс.Каталог;
Z — Яндекс.Закладки;
D — Яндекс.Директ
Я так и думал (звучит банально:) насчет C, что это проверялка, тем более, что Яндекс.Дятлы делают запрос HEAD, а не GET.
Написано Cherny в 11:45 AM
August 4, 2005
Slurp проверяет 404-ю ошибку
Полезно, все-таки, регулярно просматривать plain-логи веб-сервера — обнаружил запрос роботом Slurp некоей страницы /SlurpConfirm404/answer.htm, которой на сервере никогда не было и не планировалось создавать.
Предполагаю, что с помощью таких запросов робот Yahoo! тестирует сайт на правильность выдачи ошибки 404 Not Found, а не 301-редиректа на главную, например, как часто делается.
Я всегда при аудите сайта, в числе прочего, проверяю правильность выдачи 404-й ошибки, теперь и роботы...
Написано Cherny в 2:02 PM | Комментариев (4)
August 2, 2005
Мимикрия Yandex Blog bot
В процессе поисков фреш-бота от Яндекса обнаружил, что у робота по блогам, о котором я как-то упоминал сменился User-Agent. В настоящий момент это какие-то сиамские близнецы, с одного и того же адреса сначала YandexSomething/1.0 запрашивает robots.txt, а через пару секунд YandexBlog/0.99.101 (compatible; DOS3.30; B) уже дергает XML-ки.
Если Win16 в имена роботов добавили для обратной совместимости больше 5-ти лет назад, то как интерпретировать DOS3.30? Хотел бы я посмотреть на браузер под DOS, хотя были и такие.
P.S. Фреш-бот пока не найден, поиски продолжаются, ежедневное чтение логов восстановлено в time schedule.
Написано Cherny в 11:20 AM
March 24, 2005
Новый робот Яндекса
Встречаем нового робота Яндекса:
Yandex/1.01.001 (compatible; Win16; B); http://blogs.yandex.ru; support@blogs.yandex.ru
У меня в логах появился впервые 17-го марта. Запрашивает robots.txt и XML-файлы. Ранее те же задачи выполнял YandexSomething/1.0.
Это первый робот Яндекса с указанием в User-agent адреса сервиса и e-mail для связи, остальные такой информативностью не страдают.
Написано Cherny в 9:21 AM
February 23, 2005
Робот D Яндекса
Давно не интересовался, а вчера добавлял сайт в Яндекс и в логах вижу, что робот добавления - Yandex/1.03.003 (compatible; Win16; D) - запрашивает файл robots.txt. Когда начал запрашивать никто не знает?
Написано Cherny в 4:06 PM | Комментариев (2)
January 11, 2005
Непостоянство SEO
В середине октября выкладывал информацию о роботах основных поисковых систем, на сегодняшний день кое-что уже устарело. Для основного индексирующего робота Яндекса существенно "разбухло" поле Accept - сначала добавилось application/msword;q=0.1, application/x-shockwave-flash;q=0.1, когда Яндекс начал индексировать документы MS Word и Flash; во второй половине ноября добавилось application/vnd.ms-excel;q=0.1 - это MS Excel, а в первой половине декабря подоспел и PowerPoint - application/vnd.ms-powerpoint;q=0.1
В настояший момент поле Accept в запросе имеет следующий вид:
Accept: text/html, application/pdf;q=0.1, application/rtf;q=0.1, text/rtf;q=0.1, application/msword;q=0.1, application/x-shockwave-flash;q=0.1, application/vnd.ms-excel;q=0.1, application/vnd.ms-powerpoint;q=0.1
Раньше и не замечал, что в запросе отсутствует text/plain - при запросе robots.txt тогда Accept другой должен быть, а может у народа 406-е ошибки из-за этого и лезут?
Написано Cherny в 10:43 PM | Комментариев (4)
January 9, 2005
Робот Меты
Дождался редкого гостя!
METASpider
User-agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) METASpider
Accept: text/*
If-Modified-Since: есть в запросе
Connection: Close
Протокол в запросе: HTTP/1.0
Написано Cherny в 12:38 PM
October 29, 2004
Фальшивый робот Яндекса
Из серии "Оптимизаторы шутят".
Кто-то бродил по этому сайту с User-agent "Yandex/1.01.001 (compatible; Win16; I)", причем точно не Яндекс - IP другой, запросы к favicon.ico и файлам со стилями.
А потом на форумах люди пишут: "Ни у кого Яндекс не индексирует, а на моем сайте забирает документы..." :)
Написано Cherny в 1:06 PM | Комментариев (1)
October 28, 2004
Индексация роботом Рамблера новых сайтов
В каком-то из выпусков рассылки Андрея Иванова один из экспертов, отвечая на вопросы подписчиков, заметил, что Google новые сайты найдет сам, а в Яндекс и Рамблер их надо добавлять с помощью форм.
После запуска этого блога я его добавил в Яндекс с помощью формы, а вот в Рамблер добавлять не стал. Добавить с помощью формы нельзя, потому что домен com, а писать им письмо не захотел. Заодно решил проверить, доберется ли StackRambler до сайта без посторонней помощи.
На этой неделе обнаружил, что в базе Рамблера есть страницы блога, причем судя по датам, робот гулял по сайту уже с начала октября. Отсюда делаем вывод: новый сайт в базе Рамблера появляется достаточно быстро, в течение 2-3 недель, счетчик Rambler Top100 ставить не обязательно, достаточно нескольких ссылок на внешних ресурсах, которые Рамблер индексирует в обычном режиме.
Написано Cherny в 8:43 AM | Комментариев (3)
October 17, 2004
Некоторая информация о роботах
Выложу кое-какие данные по роботам основных поисковиков, может кому-нибудь пригодится.
StackRambler
User-agent: StackRambler/2.0 (MSIE incompatible)
From: search.support@rambler-co.ru
Connection: close
If-Modified-Since - есть в запросах
Нет заголовка Accept
Протокол: HTTP/1.0
Yandex (H)
Робот Яндекса, разбирающийся с зеркалами
User-agent: Yandex/1.01.001 (compatible; Win16; H)
From: webadmin@yandex.ru
Connection: Keep-Alive
If-Modified-Since: нет.
Accept: нет
Протокол: HTTP/1.1
Yandex (I)
Основной индексатор Яндекса
User-agent: Yandex/1.01.001 (compatible; Win16; I)
From: webadmin@yandex.ru
Connection: Keep-Alive
If-Modified-Since: есть в запросе
Accept: text/html, application/pdf;q=0.1, application/rtf;q=0.1, text/rtf;q=0.1, application/msword;q=0.1
Accept-Language: ru, uk, be, en, *;q=0.01
Протокол: HTTP/1.1
Yahoo Slurp
User-agent: Mozilla/5.0 (compatible; Yahoo! Slurp; http://help.yahoo.com/help/us/ysearch/slurp)
Accept: */*
Accept-Encoding: gzip, x-gzip (поддерживает сжатие)
Протокол: HTTP/1.0
If-Modified-Since: есть в запросе
Aport
User-agent: Aport
Accept: */*
Connection: нет
If-Modified-Since: не наблюдал ни разу
Googlebot, версия 1
User-agent: Googlebot/2.1 (+http://www.google.com/bot.html)
From: googlebot(at)google.com
Accept: text/html,text/plain
If-Modified-Since: есть
Connection: нет
Протокол: HTTP/1.0
Googlebot, версия 2
User-agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
From: googlebot(at)googlebot.com
Connection: Keep-alive
Accept: */*
Accept-encoding: gzip
Протокол: HTTP/1.1
BigMir
User-agent: BigmirSpider
Accept: */*
Connection: нет
If-Modified-Since: есть
Протокол: HTTP/1.0
MetaSpider
Давно жду, придет - поймаю и препарирую!
UPDATE:
у индексатора Яндекса расширился список типов данных в Accept, подробнее;
информация по роботу Меты.
Написано Cherny в 10:23 AM
October 16, 2004
Какую версию HTTP отдавать роботам
Какую версию протокола на самом деле надо отдавать роботам, если запросы роботов содержат версию 1.0 протокола HTTP?
На самом деле большой разницы нет. Если бы роботы реально работали в HTTP 1.0, то индексировали бы намного меньше документов. Дело в том, что клиенты версии 1.0 предполагают однозначное соответствие серверов и IP-адресов, а значит не могут работать с name-based virtual servers, т.е. роботы прошли бы мимо нескольких десятков или даже сотен сайтов, висящих на одном IP.
Я выдаю везде 1.1 и все пока работает.
Написано Cherny в 10:26 PM