
August 31, 2007
В Yahoo "улучшили" работу Slurp...
На прошлой неделе в Yahoo официально заявили об улучшении алгоритма работы поискового робота Slurp, в процессе тестирования и апдейта робота "отпустили погулять", в результате на многих сайтах от него увеличилось количество запросов и, соответственно, трафик. В Yahoo заявляют, что в будущем подобного больше не повторится, поскольку введены новые ограничения:
Don't fret, though, if you're concerned about seeing an increased load. We've initiated efforts and established policies internally to ensure this doesn't happen, even temporarily, in the future.
Западные вебмастера недовольны такими "улучшениями" и указывают на необходимость использования роботами общего кеша:
The fact that Yahoo has multiple crawlers for every division that crawl independently and don't share the common cache, now THAT's a problem that needs to be fixed.
Роботы Гугля, например, общий кеш используют, я об этом писал.
На просторах Рунета от Yahoo пользы практически никакой, а трафик, потребляемый роботом Slurp, как-никак зарубежный. На их внутренние ограничения надеяться не стоит, тем более вебмастер сам может их робота ограничить - параметр Crawl-Delay в robots.txt и можно спать спокойно.
Написано Cherny в 10:15 AM | Комментариев (0) | TrackBack
August 27, 2007
Конфиденциальность пользователей у западных поисковиков
News.com в начале августа провела небольшое иследование конфиденциальности пользователей при работе с основными поисковыми системами. Анализировались ответы на 8 вопросов, заданных по e-mail, в частности: время хранения истории поисковых запросов, время хранения данных пользователя (логов), использования персональной информации для таргетирования рекламы. По результатам опроса Ask является поисковиком, наиболее рьяно сберегающим конфиденциальность своих пользователей. Google, несмотря на изменение схемы хранения пользовательских данных, занимает 3-е место, а MSN и Yahoo! располагаются еще ниже. Однако Денни Салливан сомневается в правильности этого рейтинга.
Написано Cherny в 9:29 AM | Комментариев (1) | TrackBack
August 23, 2007
Портал для вебмастеров и оптимизаторов от Майкрософт
В официальном блоге Live Search сообщается о планах в конце осени открыть специальный сервис для вебмастеров и оптимизаторов. Работа над сервисом началась практически сразу после отключения спецоператоров поиска, сервис должен предотавлять следующие возможности:
- отслеживание и решение проблем с индексацией сайта роботом MSNBot;
- Работа с Sitemaps;
- Статистика сайта (как они ее считать будут интересно);
- Инструмент по content submission.
Пока хотят предоставить доступ группе тестеров, которым и предложено отправить свои контакты. Может быть хотят контакты вебмастеров и оптимизаторов собрать :)
В адресе используется сокращение «lswmp» из чего можно сделать вывод, что сервис будет называться Live Search WebMaster Portal.
Написано Cherny в 3:17 PM | Комментариев (2) | TrackBack
August 2, 2007
Интервью Якоба Нильсена
Недавнее интервью гуру юзабилити Якоба Нильсена (via). В основном разговр шел о будушем представлении результатов поиска, в частности как они будут выглядеть в 2010 году. Нильсен считает, что внешний вид результатов поиска не будет существенно меняться в ближайшие три года, поскольку за последние 10 лет результаты структура страницы с результатми поиска существенно не изменилась. При этом есть вероятность, что структура страница все-таки измениться с линейной на более сложную, чтобы представлять результаты поиска по разным типам информации.
Еще Нильсену не очень нравятся результаты поиска сами по себе, поскольку они основаны на popularity, т.е. на подсчете внешних ссылок. Гуру недоволен вездесущестью Википедии и постов в многочисленных блогах по информационным запросам, хотя, по его мнению, есть источники с большим кредитом доверия. С данным утверждением SEO-эксперты несогласны и считают Википедию неплохой отправной точкой при поиске информации. В Рунете, кстати, далеко не все верят в будущее ссылок и ранжирование по popularity, вспомним доклад Андрея Иванова на осенней конференции. Яндекс не просто так развивает технологию добычи фактов из текста в Яндекс.Новостях, могут ведь и к основному поиску попытаться ее прикрутить.
Не верит Нилсен и в персонализацию поиска, сколько предпочтения пользователя ни запоминай, сам же пользователь их изменяет, причем буквально в течение суток — утром ему надо одно, а к вечеру — совсем другое! :)
Упоминалась реклама в результатах поиска и использование изображений на сайтах в контексте «баннерной слепоты» — привыкания пользователя к рекламным блокам на определенных местах и последующего игнорирования этих блоков.
Заинтересованным лицам имеет смысл прочитать интервью полностью.
Написано Cherny в 9:17 AM | Комментариев (2) | TrackBack
April 17, 2007
Sitemaps просачивается в robots.txt
Вот сколько раз думал закрыть тему robots.txt, да никак не дадут!
Как многие уже успели отметить, большая западная четверка (Google, Yahoo!, MSN и Ask) приняли протокол Sitemaps, а в рамках протокола механизм Auto-Discovery, позволяющий роботам найти файлы Sitemaps самим, а не ждать сабмита от вебмастеров. Данный механизм подразумевает добавление в robots.txt директивы Sitemap, в значении которой указывается полный путь к файлу, примерно так:
Sitemap: http://webartsolutions.com/sitemap.xml
Эксперты отмечают, что:
Яндексу достаточно включить поддержку Sitemap XML и это станет стандартом де-факто и в Рунете.
Я помню дискуссию Артема Шкондина с сотрудниками Яндекса при добавлении обработки директивы Host, в частности Артем указывал, что данная директива будет непонятной, поскольку указывается главное зеркало, а не запрещаются второстепенные, формат записи приводит сразу к нескольким возможным ошибкам в записи директивы и т.д. Во многих случаях, кстати, ошибки имели место быть.
Представители большой четверки наступили на те же грабли — добавили в robots.txt еще одну неоднозначную директиву. Представим себе, как будет выглядеть запись для Яндекса в robots.txt, если Яндекс добавит поддержку Sitemaps:
User-agent: Yandex
Disallow: /dir/
Disallow: /file.html
Host: webartsolutions.com
Sitemap: http://www.webartsolutions.com/sitemap.xml
Ужасно! Что же оставется делать среднестатистическому вебмастеру? Обращаться к robots.txt-writer'у, скоро появятся такия, знающие особенности применения Allow, Crawl-delay, Host и символов подстановки. К тому времени еще какие-нибудь директивы добавят и оформят версию 2.0 протокола исключений.
Однако, как правильно заметил Филипп, пока нет смысла тратить дополнительное время на создание файла Sitemap, поскольку поисковики и так нормально находят страницы по ссылкам, а в выражении «поисковая оптимизация глубокого веба» маловато смысла.
И напоследок, некоторую мою активность по переводу протокола Sitemap на русский можно считать завершенной, в связи с появлением русскоязычной версии на официальном сайте.
Написано Cherny в 11:11 AM | Комментариев (1) | TrackBack
March 30, 2007
В Live.com отключили спецоператоры в поисковых запросах
Ранее некоторые заметили, что в поиске live.com (в прошлом search.msn.com) перестали работать некоторые спецоператоры поисковых запросов, такие как link:, linkdomain:, inurl:. Вчера в официальном блоге было опубликовано сообщение, что обработка данных операторов приостановлена из-за их использования в множестве автоматических сервисов:
We have been seeing broad use of these features by legitimate users but unfortunately also what appears to be mass automated usage for data mining. So for now, we have made the tough call to block all queries with these operators.
Обещают включить, когда сделают отсечение автоматических сборщиков данных. Стоит прочитать и комментарии - от разочарования и сравнений с Google до вполне конкретных действий пользователей:
No problem, we removed MSN/Live search from our backlink checking tools.
I added others 2 major SE for checking BL. They are doing fine :)
Страницы с результатыми поиска, кстати, запрещены в robots.txt поисковика, как это принято.
Написано Cherny в 10:23 AM | Комментариев (5)
March 20, 2007
Индексация результатов поиска
Пару недель назад Мэтт Каттс четко ответил на вопрос «Следует ли вебмастерам запрещать индексацию результатов поиска?», в результате изменили и руководство для вебмастеров:
Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don’t add much value for users coming from search engines.
Из фразы ясно, что вебмастер должен использовать правила в robots.txt, с помощью которых запрещать страницы с результатами поиска. В примерах Яндекса явно не указаны результаты поиска, как нежелательный контент, но такие приемы не понравятся модератору, особенно если результаты поиска формируются при помощи Яндекс.XML и на них ставятся статические ссылки. А такими методами в последнее время балуется один из украинских порталов, получающий значительный поисковый трафик именно на результаты поиска.
Еще ссылки по теме:
http://www.seroundtable.com/archives/012671.html
http://searchengineland.com/070312-104201.php
Написано Cherny в 11:10 AM | Комментариев (5)
March 2, 2007
NOYDIR в мета-теге для Yahoo
Как и было заявлено в октябре прошлого года, в Yahoo включили обработку мета тега ROBOTS со значением NOYDIR. С помощью этого тега вебмастер может запретить использование в результатах поиска заголовка и описания из каталога Yahoo. Пример тега:
<META NAME="ROBOTS" CONTENT="NOYDIR">
Для русскоязычных сайтов это практически ничего не меняет — во-первых, российских сайтов в каталоге Яху на сегодняшний день всего 3641, а украинских — 871; во-вторых, доля поискового трафика Yahoo для Рунета составляет всего 0,5%.
Написано Cherny в 12:45 PM
February 26, 2007
Открытые отчеты лог-анализаторов
Как «секретные» страницы попадают в индексы поисковых систем? А очень просто! Иногда достаточно поставить на этой секретной странице внешнюю ссылку и эта страница попадет в отчеты лог-анализаторов как ссылающаяся (Referer). А отчеты лог-анализаторов часто-густо лежат в открытом доступе и индексируются.
Как уберечь ссылку от попадания в отчеты о ссылающихся? Либо не оформлять ссылку, а написать ее просто текстом — тогда пользователю придется копировать ссылку из текста и вставлять в адресную строку браузера, либо запароливать свою секретную страницу — тогда она попадет в отчеты, а вот в индексы поисковиков уже навряд ли.
Кстати о «секретных» страницах. Мой небольшой эксперимент по индексации страницы с помощью тулбаров можно считать практически завершенным. Для чистоты дождусь конца месяца и напишу о результатах.
Написано Cherny в 9:58 AM | Комментариев (2) | TrackBack
January 27, 2007
Google говорит нет Googlebombing
В блоге для веб мастеров представители Google заявляют об изменениях в алгоритме поиска, благодаря которым должно исчезнуть такое явление, как Googlebombing. Денни Салливан, в свою очередь, дает ретроспективу этого явления и разбирает вопрос корректности решения этой проблемы, если Googlebombing можно назвать проблемой.
Технология Googlebombing сама по себе довольно проста и основывается на особенностях поисковых алгоритмов некоторых поисковых систем, а именно — учете текста ссылок при определении рейтинга страниц, на которые эти ссылки ведут, или ссылочном ранжировании. То есть слова из ссылки как бы добавляются к текст страницы, причем с учетом веса ссылающейся страницы. Ссылочное ранжирования хорошо работает в Гугл и даже слишком хорошо — в Яндексе. А вот Рамблер как ни бомби — толку будет мало. Если же к этому рецепту присовокупить социальную составляющую (выражаясь модными словами), а проще говоря — если поставить значительное количество ссылок с одинаковым текстом с разных сайтов на одну и ту же страницу, то эта страница займет хорошие позиции по запросу, даже если слова из запроса совсем не встречаются в тексте страницы.
Наиболее известным примером Googlebombing считается первое место страницы с биографией Джорджа Буша по запросу miserable failure (жалкий неудачник), причем первое место страница удерживала более двух лет. Аналогичные фокусы проделывались и в рунете с сайтами президента России Путина в 2006 году и кандидата в президенты Украины Януковича в 2004. Правда американской стабильности в нашем случае замечено не было — сайты в топах по бомбовым запросам долго не висели.
В Гугле не корректировали результаты поиска «вручную», а предпочли изменить алгоритм. Об изменениях алгоритма рассуждает Филипп Ленссен, кроме этого дает сравнительную таблицу наиболее известных случаев бомбинга, включая и российский случай. Филипп пишет, что следует анализировать структуру ссылочных графов для отсечения неестественных связей (ссылок) между узлами (страницами). Я же могу сказать, что для бомбинга характерно как отсутствие фразы в тексте самой страницы, так и одинаковый текст ссылок с большого количества страниц. А дальше уже анализ графов, конечно.
Написано Cherny в 12:40 AM | Комментариев (4)
December 29, 2006
Sitemaps на русском
А вот и подарок номер два! В связи с тем, что технология Sitemaps перестала быть только Google, а стала общей инициативой Google, Yahoo и MSN, я решил перевести документы по стандарту на русский язык. Итак, русская версия протокола Sitemaps 0.9! К сожалению из-за начавшихся провожаний старого года не успел полностью перевести FAQ, но за оставшиеся три дня постараюсь все-таки его добить.
Некоторые пункты протокола у меня вызвали некоторое недоумение, в частности настоятельная рекомендация размещать файлы Sitemaps в корневой директории сайта, а при размещении в каталоге игнорирование адресов вне этого каталога. Ну да ладно!
Да, документация еще не вычитана, так что если обнаружите ошибки или просто опечатки - стучитесь, буду исправлять.
Написано Cherny в 10:57 AM | Комментариев (2)
December 20, 2006
Контент и ссылки - два кита поискового продвижения
Контент и ссылки являются основными составляющими успешного поискового продвижения веб-сайтов. Ссылки входящие, конечно же! Там, где присутствует качественный контент, там с большой вероятностью появляются хорошие входящие ссылки, а сейчас, во время процветания различных веб-сервисов, можно утверждать и обратное: там где присутствуют ссылки, может появится и контент, но не факт, что качественный. И то, и другие, возможно только при наличии аудитории.
Но вернемся к ссылкам и контенту. Сотрудники Гугла после посещения профильных оптимизаторских и вебмастерских мероприятий и дискуссий, как у нас принято говорить, в кулуарах, решили ударить блогопробегом как по ссылкам, так и по контенту и вопросу его дублирования.
Ссылки
В первом посте рассматривается вопрос, как же лучше получать на свой сайт массив входящих ссылок — медленно наращивая его за счет качественного контента и грамотной стратегии продвижения или быстрыми темпами за счет применения не слишком чистых приемов и покупки ссылок. Примечательно, что покупка ссылок в данном посте явно приравнивается к спаму:
link spamming tactics such as buying links
Опуская обычные для таких случаев ссылки на руководство для вебмастеров, отметим следующие момент — Google существенно изменил алгоритм взвешивания ссылок, кроме этого несколько человек брошены на улучшение эффективности алгоритма. Я бы предположил добавление нескольких коэффициентов для довзвешивания ссылок, причем эти коэффициенты должны отличаться, например, для соседних ссылок на одной и той же страницы. Сообщается также о практической бесполезности взаимных ссылок, то есть прямого обмена, но это и так все знают.
В качестве рецепта рекомендуется использовать социальный веб для построения массива входящих ссылок. Хотя мне кажется, что социальный веб вполне себе освоил nofollow.
Кстати, алгоритм отлова нетематических невзаимных ссылок Игорь Ашманов нарисовал на листике бумаги во время фуршета на конференции, все довольно просто, надо отслеживать одинокие связи между "клубками" графа ссылок. Правда мне становится не очень хорошо, когда я пытаюсь представить ты часть ссылочного графа Яндекса, где сосредоточены коммерческие тематики.
Контент (дубликаты)
Во втором посте Адам Ласник дает определение дубликатам (duplicate content) и как обычный вебмастер может бороться с появлением таких дубликатов. Дубликаты - это блоки контента в пределах одного домена или ряда доменов, которые в точности соответствуют или сильно схожи на другие блоки контента, расположенные в других местах. Темы форумов в различных вариантах просмотра, сортировка списков, каталоги товаров, которые хранятся и, что намного хуже, линкуются по разным адресам (саттелиты не напоминает?)
Борется Гугл с дубликатами при помощи специальных фильтров при формировании результатов поиска, попытками отсеить версии для печати, корректировкой алгоритма индексации ресурсов, уличенных в дублировании и т.д.
Что же может сделать вебмастер? Некоторые методы я описывал в докладе о технических аспектах в поисковом продвижении, а вот что предлагают в Гугле:
- Изначально блокировать индексацию второстепенных страниц
- Использовать 301-й редирект при реструктуризации сайта для перенаправления на новые версии страниц
- Не генерить множество различных ссылок на одни и те же страницы
- Использовать домены второго уровня
- Понимать как работает CMS-сайта
И еще ряд рекомендаций...
Поскольку это все-таки запись в блоге, а не статья, то я здесь поставлю точку и пойду спать без ломания мозгов и формулирования выводов.
Написано Cherny в 1:03 AM
December 19, 2006
Полное запрещение индексации сайта
Сбылась мечта и... В общем, потребовалось на одном проекте полностью запретить индексацию поисковыми системами, от корня!
Нет ничего проще, две строчки в известном файле были прописаны 7-го декабря:User-agent: *
Disallow: /
Все поисковики ведут себя относительно прогнозируемо. Рамблер, например, проводит проверку запрещающих правил проиндексированным адресам раз в неделю, как правило на выходных, поэтому до выходных можно запрещать Рамблеру любые адреса из ранее проиндексированных и это ни на что не повлияет, они даже будут переиндексироваться, но на выходных карета превратится в тыкву, кони — в мышей, StackRambler сверится с актуальным robots.txt и выкинет все лишнее из базы.
Интересно ведет себя Google. После изменения robots.txt новые адреса, конечно, не индексируются, а уже известные — не переиндексируются заново, однако Гугл прикидывается шлангом и из индекса страницы не удаляет, там лежат сохраненные копии от 5-го декабря и ранее! Более 6 тысяч успешно сохраненных страниц! Хотя для Гугля это скорее правило, буквально на прошлой неделе я имел счастье лицезреть кеш страницы в дополнительном индексе (Supplemental Results) от середины апреля, причем всем роботам было запрещено индексировать страницу где-то в начале мая.
Таким образом Гугл интерпретирует запрещающее правило в robots.txt как запрет индексации и переиндексации, но не как требование удаления уже проиндексированной страницы из индекса.
Написано Cherny в 12:59 AM
November 20, 2006
SiteMaps становится общей инициативой
Пока был на конференции, пропустил одну важную и интересную новость - протокол Sitemaps будет поддерживаться всеми основными поисковиками: Google, Yahoo, MSN Live. Подробности о протоколе можно узнать на сайте http://www.sitemaps.org/.
Написано Cherny в 11:52 AM
November 3, 2006
Yahoo Slurp и robots.txt
Мой (потенциальный) доклад о robots.txt на московскую конференцию устаревает еще до его выхода!
В официальном блоге Yahoo опубликована информация о включении обработки символов подстановки в robots.txt для робота Slurp, в директивах Disallow можно использовать «*» — любые символы, и «$» — завершение строки адреса:
we have just updated Yahoo! Slurp to recognize two additional symbols in the robots.txt directives — "*" and "$".
Есть еще два интересных момента в этом сообщении:
- В качестве имени робота в User-agent используется Yahoo! Slurp, а не просто Slurp, как описано в разделе помощи.
- В примерах кроме всего прочего используется нестандартная директива Allow, которую, опять же, в официальном разделе помощи я не встречал.
Почти в конце заметки подтверждается обработка Allow:
Oh, by the way, if you thought we didn't support the 'Allow' tag, as you can see from these examples, we do.
По-моему, робот Yahoo Slurp теперь поддерживает наибольшее количество нестандартных директив и расширений, включая директиву Crawl-delay.
Написано Cherny в 9:44 AM
November 1, 2006
Рамблер купили вслед за его каналом
По сообщению Lenta.ru медиахолдинг Проф-Медиа приобрел 48,8% акций Рамблера и заключил соглашение о приобретении еще 6%.
Также заявляется о развитии и новом уровне:
Пакет акций «Рамблер Медиа», которая сконцентрируется исключительно на онлайн-бизнесе, станет важнейшим элементом в стратегии развития «Проф-Медиа» в интернете. В качестве стратегического инвестора на российском медиарынке мы рассчитываем закрепить впечатляющие успехи компании и вывести ее на новый уровень развития (в том числе и через слияния и поглощения), поддерживая преемственность менеджмента и сложившиеся в компании высокие стандарты корпоративного управления.
Написано Cherny в 9:32 AM
October 25, 2006
Рамблер продал свой TV
Рамблер продал свой телевизионный канал. Хотелось бы надеяться, что освободившиеся ресурсы действительно будут направлены на развитие других проектов, в частности интернет, а еще в еще большей частности — на развитие поиска. Здоровая конкуренция рынку не помешает. Вернее сказать, рынкам!
Написано Cherny в 11:44 AM | Комментариев (1)
Yahoo поддерживает мета-тег NOODP
В официальном блоге Yahoo заявлено о поддержке мета-тегов <meta name="ROBOTS" content="NOODP">
и <meta name="Slurp" content="NOODP">
Напомню, что эти теги используются для запрета использования описания из каталога ODP в результатах поиска. Следует заметить, что с помощью этого тега нельзя запретить описание из Yahoo! Directory, а это несколько непоследовательно.
Написано Cherny в 11:08 AM | Комментариев (2)
October 11, 2006
Осень пришла: апдейт Yahoo, PageRank не изменится до Нового Года
В официальном блоге Yahoo очередное сообщение об очередном апдейте, Мэтт Каттс пишет о прошедшем апдейте инфраструктуры Google в пятницу 6-го октября, недавнем экпорте видимых значений PageRank и говорит, что обновлений PageRank в тулбаре не планируется до Нового Года:
We just did a PageRank export, so I wouldn’t expect to see another export until the new year.
Написано Cherny в 10:56 AM
September 6, 2006
Офис разработки Яндекса в Питере
Яндекс открыл в Питере офис разработки. (via)
Теперь понятно, откуда такой апдейт - это открывалься питерский филиал! :)
Написано Cherny в 2:05 PM
September 5, 2006
Ну, апдейт на Яндексе
Журналисты на интервью разбудили Сегаловича, Сегалович к сентябрю окончательно разбудил отдел разработки.
Начинают работать новые механизмы, где по чистке доров, где фильтры ссылок с морд. Давно пора было перетрясти эту ссылочную биржу, в которую превратился подсевший на трафик с Яндекса рунет.
Контент рулит, господа присяжные заседатели!
Написано Cherny в 1:10 AM | Комментариев (4)
August 28, 2006
Очередной апдейт Yahoo
По уже сложившейся традиции Yahoo сообщает об апдейтах в своем блоге. Попутно зазывают вебмастеров регистрироваться в Site Explorer.
Написано Cherny в 10:05 AM
August 4, 2006
Yahoo ищет SEO-специалиста
Немецкое отделение Yahoo ищет SEO-специалиста. (via)
Все рабочие обязанности и требования к соискателю внятно расписаны. Возникает только вопрос о продвижении продуктов Yahoo в самом Yahoo и знании особенностей алгоритма нанимателя! :)
Написано Cherny в 9:17 AM
August 2, 2006
msnbot переименовали
Робота поисковой системы от Майкрософт переименовали, вернее отпочковали от него узкоспециализированных агентов, в частности:
msnbot-products — бот «Shopping», не знаю очем речь, подскажите, кто в курсе;
msnbot-news — новостной робот;
msnbot-media — робот поиска по изображениям, теперь можно для экономии запретить индексацию сайта роботу для картинок, но открыть всем остальным;
msnbot — робот для основного поиска.
Написано Cherny в 12:05 AM
July 17, 2006
Апдейт Yahoo!
Это далеко не так важно, как апдейты Яндекс или Google, но тем не менее — 14-го июля обновился индекс Yahoo. Представители компании периодически заявляют о своих апдейтах в собственном блоге.
Для русскоязычных сайтов, на мой взгляд, Yahoo сейчас как далекая красивая страна за горизонтом — много всего интересного про нее слышали, но никто ее не видел. Гораздо более интересно отслеживать MSN Search, трафика дает больше, поскольку по умолчанию стоит в IE.
Написано Cherny в 9:56 AM
June 21, 2006
Если бы веб-сайты были пультами ДУ
Если бы веб-сайты были пультами дистанционного управления. Google
Yahoo!

Больше здесь
Написано Cherny в 9:28 AM
June 15, 2006
ЧМ 2006 и поисковые системы
Поисковики по разному обыгрывают Чемпионат Мира по футболу в Германии.
Яндекс
На главной странице Яндекса опубликована ссылка на соответствующую ветку новостей, кроме этого в телепрограмме отдельным блоком трансляции матчей со временем и кратким анонсом.
Рамблер
Рамблер просто запустил отдельный проект FIFA-2006.
Если в Google ввести через пробел два названия стран, сборные которых играли в недавнем времени, то он просто выдаст счет матча, а также время следующего ближайшего матча одной из команд. По такому запросу, например, можно убедиться, что вчерашний матч нашей сборной не приснился мне в кошмарном сне! Хотя чуда ждать, конечно, не стоило...
Написано Cherny в 10:03 AM | Комментариев (2)
January 27, 2006
Новый украинский поисковик
В семье украинских поисковиков ожидается прибавление — портал Online.Ua выкатил свой собственный поисковый движок, который пока находится на этапе тестирования. (via)
Контекстные рекламные объявления на портале показываются директовские. Таким образом уже две украинские поисковые системы являются рекламными площадками Яндекса: Бигмир, где объявления директа транслируются с ноября и Online.Ua — с конца декабря.
Написано Cherny в 10:39 AM | Комментариев (6)
January 25, 2006
Сколько было сайтов 78 лет назад?
Статью про Мету я не дочитал, не смог перевалить за третий абзац! Всего лишь дефис...
А ведь правда — 78 лет назад (в 1928 году) интернет-сайтов было намного меньше, чем теперь!

Написано Cherny в 10:41 AM | Комментариев (2)
December 13, 2005
Alexa открывает разработчикам индекс
Alexa Web Search открывает разработчикам поисковый индекс, который собирался и обновлялся с 1996-го года роботом ia_archiver. (via).
Как они пишут: теперь каждый может создать новые поисковые сервисы без инвестирования миллионов долларов в индексацию, хранение и обработку данных, серверные технологии.
Три «снимка» под 100 терабайт каждый. Просто так не качнешь!
Написано Cherny в 9:53 AM
November 29, 2005
Поисковики и 301-й редирект
Это вовсе не сказка для оптимизаторов, а очень даже быль.
После споров на тему передачи всяких ссылочных факторов через серверный редирект 301 Moved Permanently, было принято решение поставить несложный эксперимент и посмотреть, что же на самом деле происходит.
Из поисковиков наибольший интерес представляли Google и Яндекс. Проверялось ссылочное ранжирование или влияние текста ссылки на ранжирование страницы, на которую эта ссылка ведет. Однозначно проверить «просачивание» Google PageRankTM и Яндекс вИЦ через редирект проблематично, поскольку измененяется отображение PageRank редко, а вИЦ и посмотреть негде, разве только оценить косвенно.
Как это было
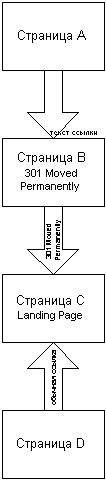 Схема эксперимента на картинке. Были специально созданы страницы «B» (страница с редиректом) и «C» (конечная страница), страница «А» (ссылающаяся страница) существовала ранее. Страница «B» безусловно отправляла всех на «C» с кодом 301, текст ссылки на «А» был абсолютно уникальным, то есть больше в интернете нигде не встречался, включая конечную страницу. Дополнительно следует отметить, что страница с со ссылкой и страница с редиректом находились на одном домене, а конечная страница — на другом.
Схема эксперимента на картинке. Были специально созданы страницы «B» (страница с редиректом) и «C» (конечная страница), страница «А» (ссылающаяся страница) существовала ранее. Страница «B» безусловно отправляла всех на «C» с кодом 301, текст ссылки на «А» был абсолютно уникальным, то есть больше в интернете нигде не встречался, включая конечную страницу. Дополнительно следует отметить, что страница с со ссылкой и страница с редиректом находились на одном домене, а конечная страница — на другом.
Первым через два дня появился Googlebot, который запросил «B» и практически сразу «C». Яндекса пришлось ждать довольно долго, причем основной индексатор Яндекса запросил только страницу с редиректом и, получив 301 Moved Permanently, успокоился.
Примерно через две недели на «C» была поставлена обычная ссылка с четвертой страницы с неуникальным текстом, специально для Яндекса. Через неделю индексатор Яндекса все-таки добрался до конечной страницы и после пары апдейтов она появилась в основной базе.
Результаты
В процессе эксперимента выяснилось, что пока робот Яндекса собирается индексировать что-либо через 301-й редирект, то GoogleBot успевает все проиндексировать, после чего еще пять раз перезапросить не только конечную страницу, но и страницу с редиректом и продолжает это делать по сей день. Пока суть да дело роботы Yahoo и MSN тоже постарались, правда неясно, или через редирект, или по обычной ссылке достали конечную страницу.
В результате обрисовалась следующая картина:
- Google прекрасно индексирует новые страницы, доступные только через редирект, при этом ссылочное ранжирование работает для конечной страницы и она получает прибавку PageRank. Можно сказать, что для Google страницы с редиректом как бы не существует, а ссылка стоит с «А» сразу на «C». Можно также говорить, что страница с редиректом «приклеивается» к конечной странице.
- Яндекс плохо индексирует страницы, доступные только через редирект, при этом текст ссылки на ранжирование конечной страницы не влияет, то есть ссылочное ранжирование через 301-й редирект не работает.
- Yahoo и MSN специально не проверялись, но «походу» ссылочное через редирект в них тоже не работает.
Post Scriptum
Источником эксперимента на самом деле были дискуссии о применении 301-го подокументного редиректа для однозначной и корректной склейки зеркал. Данный эксперимент ничего не доказал, поскольку при склейки доменов, а не документов, ссылки на дополнительные зеркала могут и учитываться Яндексом при ранжировании.
В ближайшее время планирую повторить эксперимент, а также дополнительно проверить редирект 302 Moved Temporary по аналогичной схеме и учет текста ссылок для склеенных зеркал, когда ссылки ведут на дополнительное зеркало, а домены склеены при помощи подокументного 301 Moved Permanently.
Написано Cherny в 5:01 PM | Комментариев (21)
November 18, 2005
Бигмир ищет по миру
Украинский портал Bigmir.Net дает возможность искать по всему рунету.
Сервис реализован на Яндекс.XML, так что украинские пользователи теперь могут искать на Яндексе в UAIX.
В результатах поиска не выводится рубрики Яндекс.Каталога и даты последнего изменения страниц, зато присутствуют объявления Яндекс.Директ и Яндекс.Маркет. Объявления бигмировской контекстной рекламы Adsearch также присутствуют.
Написано Cherny в 9:48 AM
November 9, 2005
Яндекс.Директ на Бигмире
Объявления Директа начали транслироваться на портале Bigmir.Net (via).
А что Бигмир теперь со своим AdSearch делать будет?
Или прикрутят к своим результатам еще и Бегун для полного комплекта?
Написано Cherny в 9:45 AM
October 24, 2005
MSN имеет PageRank 2
MSN доигрался с редиректами (via)
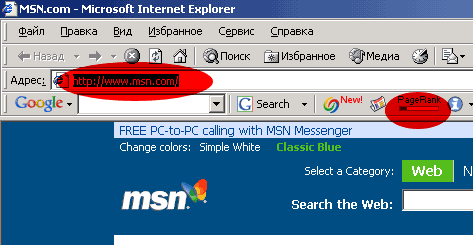
А все потому, что Googlebot, скорее всего, получает на главной странице 302-й редирект:
HTTP/1.0 302 Moved Temporarily
Date: Mon, 24 Oct 2005 09:20:40 GMT
Server: Microsoft-IIS/6.0
X-AspNet-Version: 1.1.4322
Location: http://www.msn.com/?GUID=59398b6e485b452f841e2343741262b1
Set-Cookie: MC1=V=3&GUID=59398b6e485b452f841e2343741262b1; domain=.msn.com; expires=Mon, 04-Oct-2021 19:00:00 GMT; path=/
Cache-Control: private
Content-Type: text/html; charset=utf-8
Content-Length: 174
Connection: close
На днях выложу результаты своего небольшого эксперимента с 301-м редиректом.
Написано Cherny в 11:23 AM
May 18, 2005
Дождался реакции Рамблера
Сегодня обнаружил, что Рамблер вычистил из своего индекса все страницы, запрещенные в robots.txt. Ровно месяц ему понадобился. То ли штатная процедура наконец-то отработала, то ли мое письмо кто-то прочел.
Написано Cherny в 1:10 PM
May 11, 2005
У Рамблера барахлит удалялка
Уже около месяца на сайте лежит robots.txt, запрещающий индексацию сайта всем роботам. Яндекс сработал на удивление быстро — недели не прошло, а в базе уже ничего нет. А вот механизм Рамблера по удалению запрещающих страниц, о котором я уже писал, что-то барахлит: страницы из базы не удаляются, хорошо хоть новые не индексирует. На прошлой неделе написал письмо в службу поддержки — реакции никакой. То ли они все в Египте дайвингом занимаются, то ли робот сиротой остался.
Сейчас положил robots.txt, где добавил секцию специально для StackRambler, может он общие правила плохо воспринимает.
Написано Cherny в 11:57 AM
April 14, 2005
Поиск в Yahoo и Google одним кликом
Я пропустил сообщение об открытии сайта Yagoohoogle, с помощью которого можно одновременно просматривать результаты поиска от Google и Yahoo в одном окне. Результаты поиска выводятся в двух вертикальных фреймах, причем границу фреймов можно передвигать — очень удобно.
Следует отметить, что Вебпланета стала использовать новости сайта ITUA.info, с чем я ребят из ITUA и поздравляю!
Написано Cherny в 10:35 AM | Комментариев (1)
April 4, 2005
Рамблер изменил дизайн результатов поиска
Что-то я пропустил когда точно это произошло. Да и сообщений никаких не было, вроде. Ассоциации справа — намного удобнее чем раньше!
Написано Cherny в 10:13 AM
February 24, 2005
Yahoo! Image Search
В официальном блоге Yahoo! появилась заметка о поиске по изображениям по заголовком Image Search: Does Size Matter?
Названа цифра в 1,5 миллиарда изображений в поисковом индексе, при этом говорится следующее:
Being the largest image search engine simply isn't enough. As we continue to expand the index size, we're also working hard to make image searching easier and faster than ever.
В расширенном поиске доступны такие опции, как
- Размер изображения (Size): wallpaper, large, medium, small;
- Цвет (Coloration): color only, black and white only;
- Поиск по доменам или сайту (Site/Domain);
- "Семейный" фильтр (SafeSearch Filter).
Написано Cherny в 11:38 AM
October 27, 2004
Новости на Meta.ua
Украинская поисковая система Meta запустила бета-версию новостного сервиса news.meta.ua.
Принцип работы такой же, как у Яндекса: жесткий рубрикатор, новости тянутся из RSS-фидов, на текущий момент 28 украинских источников, частота опроса источников - 5-10 минут.
Заголовки новостей и полнотекстовый индекс сохраняются в архиве. Связаны ли индекс новостей и общий индекс, пока сказать не могу.
В заключении:
В планах Меты расширение числа источников и предоставляемых посетителям дополнительных сервисов.
Я уже обнаружил небольшой баг, о чем им написал. ;)
Написано Cherny в 10:53 PM
October 23, 2004
Мета активизировалась
В последние две недели Meta проснулась: в базе страницы от 15.10, METASpider по сайтам бродит.
Зато Яндекс замер, только в очередной раз сайты из категории Туризм в выдаче появились. А полноценных обновлений будем ждать после окончания соревнований по поиску. Если во время кубка апдейт сделать, то сами организаторы ответы на свои вопросы найти не смогут! :)
Написано Cherny в 5:44 PM